cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
AI大模型系列:(九)LlamaIndex入门介绍
一、LlamaIndex介绍
LlamaIndex 是一个为实现「上下文增强」的大语言模型应用框架。其更偏向RAG应用的流程,面向RAG的功能更丰富全面。Github 地址
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善,相关地址如下:
- Python 文档地址:https://docs.llamaindex.ai/en/stable/
- Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
- TS 文档地址:https://ts.llamaindex.ai/
- TS API 接口文档:https://ts.llamaindex.ai/api/
python通过如下命令安装:
Typescript通过如下命令安装:
npm install llamaindex
# 通过 yarn 安装
yarn add llamaindex
# 通过 pnpm 安装
pnpm add llamaindex
其核心模块如下图所示:
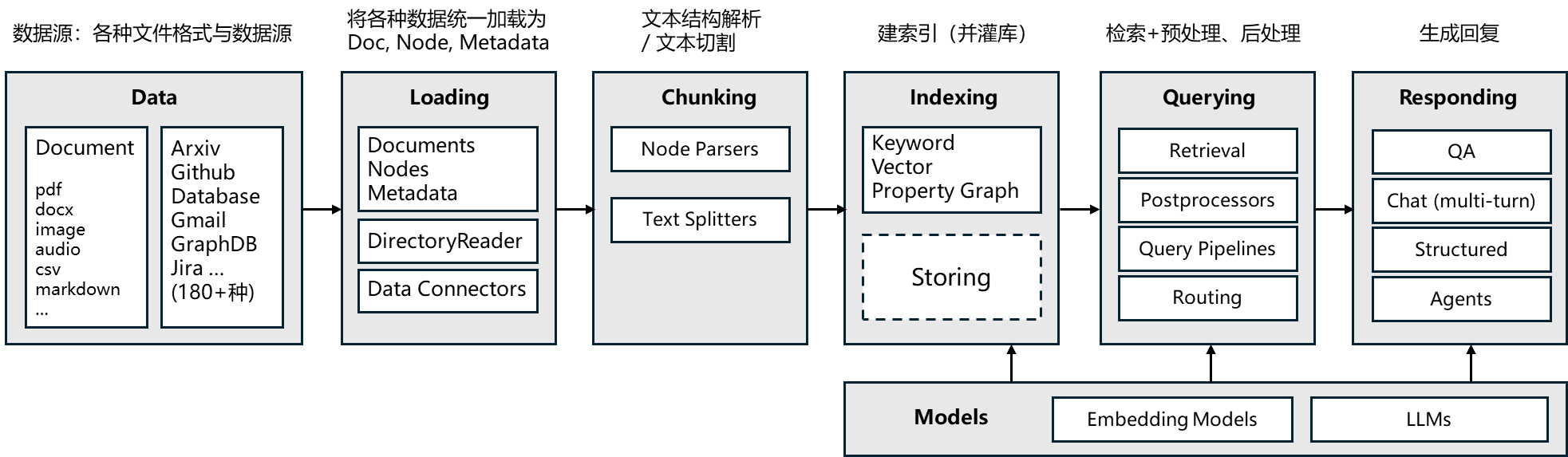
二、数据加载
2.1、数据加载器
LlamaIndex库提供了多种文件加载器,用于从不同类型的数据源读取文档。甚至还有bilibili的弹幕与视频加载器
LlamaIndex定义了加载器的抽象基类:BaseReader,它定义了一些基本的方法和属性,这些方法和属性是所有数据加载器都应该实现的。开发者也可以通过继承 BaseReader创建自定义的数据加载器。
下面仅对一些常用的加载器做简单的介绍。其他加载器可查看官方API
1、内置的文件加载器
如下一些可能常用的加载器:
- SimpleDirectoryReader:从文件系统中指定目录读取文档。
- SimpleFileReader:从单个文件中读取文档。
- JSONReader:从 JSON 文件中读取文档。
- PptxReader:从 PPT 文件中读取文档。
- PDFReader:从 PDF 文件中读取文档。
- DOCXReader:从 Word 文档(DOCX 格式)中读取文档。
更多内置的加载器可以查看,官方文档,其上也有示例,就不多做介绍。
2、连接第三方服务的数据加载器
llama_index 库除了支持从本地文件系统加载数据外,还支持从第三方服务和数据库加载数据。以下是一些常见的第三方服务数据加载器及其用途:
3、更多的第三方发布的加载器也可以从LlamaHub(https://llamahub.ai/)上搜索得到。
2.2、SimpleDirectoryReader简单介绍
我们通过SimpleDirectoryReader来了解加载器的处理方式。
SimpleDirectoryReader类用于从文件系统中指定目录读取文档。它的设计目的是简化从多种文件类型中提取内容的过程。
支持的文件类型:
- csv - comma-separated values
- docx - Microsoft Word
- epub - EPUB ebook format
- hwp - Hangul Word Processor
- ipynb - Jupyter Notebook
- jpeg, .jpg - JPEG image
- mbox - MBOX email archive
- md - Markdown
- mp3, .mp4 - audio and video
- pdf - Portable Document Format
- png - Portable Network Graphics
- ppt, .pptm, .pptx - Microsoft PowerPoint
具体来说,SimpleDirectoryReader 会根据文件扩展名自动选择合适的文件读取器来处理不同类型的文件。
以下是 SimpleDirectoryReader 的工作逻辑:
- 遍历目录:SimpleDirectoryReader 会遍历指定目录中的所有文件和子目录。
- 文件类型检测:对于每个文件,它会检查文件的扩展名,以确定文件的类型。
- 选择读取器:根据文件类型,SimpleDirectoryReader 会选择合适的文件读取器。例如,对于 .txt 文件,它会使用文本文件读取器;对于 .pdf 文件,它会使用 PDF 文件读取器。
- 读取文件:选定的文件读取器会读取文件内容,并将其转换为 llama_index 中的 Document 对象。
- 返回文档列表:SimpleDirectoryReader 会将所有读取的 Document 对象存储在一个列表中,并返回这个列表。
如果默认的加载器不适用我们的业务需求,也可以指定加载器:
示例:(如下代码需要先执行命令加载依赖:pip install pymupdf)
from llama_index.readers.file import PyMuPDFReader
reader = SimpleDirectoryReader(
input_dir="./data", # 目标目录
recursive=False, # 是否递归遍历子目录
required_exts=[".pdf"], # (可选)只读取指定后缀的文件
file_extractor={".pdf": PyMuPDFReader()} # 指定特定的文件加载器
)
documents = reader.load_data()
print(documents[0].text)
调用 SimpleDirectoryReader 的 load_data() 方法时,它会返回一个包含读取文件内容的Document列表。每个Document通常是一个字典,包含文档的元数据和内容。
2.3、文档(Document)
文档(Document)和节点(Node)对象是LlamaIndex中的核心抽象概念。文档是围绕任何数据源的通用容器——例如,PDF、API输出或从数据库检索的数据。
Document可以手动构建,也可以通过数据加载器自动创建。默认情况下,所有的数据加载器都通过load_data函数返回文档对象。如果要进行手动创建Document可以通过如下方式:
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
默认情况,每个文档可能包含以下字段:
- relationships:一个包含与其他文档/节点关系的字典。
- metadata: 包含文档的其他元数据,如文件名、路径、创建时间等。
代码示例:
from llama_index.readers.file import PyMuPDFReader
# 创建一个SimpleDirectoryReader实例,用于从指定目录读取PDF文件
reader = SimpleDirectoryReader(
input_dir="./data", # 指定要读取的目标目录
recursive=False, # 设置为False,表示不递归遍历子目录
required_exts=[".pdf"], # 设置只读取.pdf后缀的文件
file_extractor={".pdf": PyMuPDFReader()} # 指定特定的文件加载器
)
# 使用load_data方法加载数据,返回一个包含Document对象的列表
documents = reader.load_data()
# 遍历每个Document对象,并打印其ID、文本内容和元数据
for doc in documents:
print(f"Document ID: {doc.doc_id}") # 打印文档ID
print(f"Text: {doc.text}") # 打印文档文本内容
print(f"Metadata: {doc.metadata}") # 打印文档元数据
print("\n") # 打印空行,用于分隔不同文档的输出
TIP:更多的 PDF 加载器还有 SmartPDFLoader 和 LlamaParse, 二者都提供了更丰富的解析能力,包括解析章节与段落结构等。但不是 100%准确,偶有文字丢失或错位情况,建议根据自身需求详细测试评估。
更多Document详细内容,可以自行查阅:Document官网介绍
三、 文本切分与解析
3.1、节点(Node)
为方便检索,LlamaIndex通常会把数据加载后获得的Document切分为Node,Node就是Document切分后的“块(Chunk)”,无论是文本、图像还是其他内容最后切分后都为此数据结构。
Node中还包含与其他节点和索引结构的元数据和关系信息。
节点对象获取:可以选择直接定义节点及其所有属性,也可以选择通过NodeParser类将源文档“解析”成节点。
手动构件节点对象:
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
nodes = [node1, node2]
更多Node相关类容可查阅:官方文档
通过NodeParser解析的方式获取Node下文继续讲解。
3.2、NodeParser
通过官方API文档可知,NodeParser算是LlamaIndex其他解析器的基类,提供了一些基本的文本解析功能。
通过继承 NodeParser,其他解析器类可以复用 NodeParser 中的基本功能,并根据需要添加或修改特定的解析逻辑。
例如:
TextSplitter继承于NodeParser,它专门用于将文本分割成较小片段的类。它不涉及元数据的提取,只是简单地将文本分割成多个部分。这对于处理长文本特别有用,因为它可以将长文本拆分成更易于管理的片段。
MetadataAwareTextSplitter 最终就是继承自 TextSplitter,它在分割文本的同时还能提取元数据。这个类结合了 TextSplitter 和 NodeParser 的功能,既能够分割文本,又能够提取和附加元数据。
3.3、文本切割
LlamaIndex 提供了丰富的文本切割实现,例如:
- SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
更多文本切割类可以查看官方文档
如果官方实现类无法满足业务需求,也可以自定义TextSplitter实现,示例:
# 测试文本
long_text = """
这是一个测试文本,它会根据逗号分割成多个文本片段。
每个文本片段的长度不会超过 chunk_size,并且前后文本片段之间会有一定的重叠。
"""
class CommaTextSplitter(TextSplitter):
def split_text(self, text):
# 根据逗号分割文本
chunks = text.split(',')
# 去除每个片段前后的空白字符
chunks = [chunk.strip() for chunk in chunks]
return chunks
# 创建 CommaTextSplitter 实例
splitter = CommaTextSplitter()
# 使用 CommaTextSplitter 分割文本并提取元数据
chunks = splitter.split_text(long_text)
# 输出分割后的文本片段
for chunk in chunks:
print(f"Text: {chunk}")
print("-" * 50) # 打印分隔线
3.4、结构性文档解析
对于结构性文档解析,LlamaIndex也提供了丰富的实现类。
- HTMLNodeParser:用于解析 HTML 文档,并将其转换为 LlamaIndex 可以处理的节点。其从 HTML 文档中提取文本内容时会忽略 HTML 标签。但其不是简单的删除标签而已,会识别在不同HTML标签,在处理时可以进行不同的逻辑解析。
- JSONNodeParser:用于解析 JSON 数据,并将其转换为 LlamaIndex 的节点。其能够处理嵌套的 JSON 数据,并将其转换为节点结构。
- MarkdownNodeParser:用于解析 Markdown 文档,其能够处理 Markdown 文档中的不同元素,如标题、列表、代码块等,并将其转换为 LlamaIndex 的节点。
更多结构文档解释相关知识可以查看官方文档
在此仅通过JSONNodeParser演示解析JOSN:
from llama_index.core.node_parser import JSONNodeParser
# 示例 JSON 数据
json_data = '''
{
"title": "示例文档",
"content": "这是一个用于演示的示例文档。",
"sections": [
{
"heading": "第一部分",
"text": "这是第一部分的内容。"
},
{
"heading": "第二部分",
"text": "这是第二部分的内容。"
}
]
}
'''
# 使用 load 方法加载 JSON 数据
documents = [Document(text=json_data, metadata={"type":"test"})]
# 创建一个 JSONNodeParser 实例
parser = JSONNodeParser()
# 使用 parse 方法解析 JSON 数据
nodes = parser.get_nodes_from_documents(documents)
# 输出解析后的节点
for node in nodes:
print(f"节点 ID: {node.id_}")
print(f"节点内容: {node.text}")
print(f"元数据: {node.metadata}")
print("\n")
四、 索引与检索
数据进行加载和切割后,就需要把数据放到检索引擎里去,LlamaIndex为我们提供了与检索引擎之间的交互封装,支持可更换的存储组件,使用户能定制:文档存储、索引存储、向量存储、属性图存储、聊天存储。
当前只以向量存储为例进行介绍,更详细功能可以查看:官方文档
4.1、接入向量数据库
TIP:之前的文章中有介绍过向量检索和向量数据库,如果需要可点击链接查看。
LlamaIndex对20多向量数据库进行了封装:官方API文档、官方示例、官方指南
在此仅以SimpleVectorStore为例进行介绍,SimpleVectorStore是LlamaIndex中的一个简单向量存储实现,它将向量存储在内存中。
当你将数据存入SimpleVectorStore时(调用SimpleVectorStore中的add方法)实际上是在SimpleVectorStore中构建了一个简单的索引,以便在查询时能够快速找到与给定查询向量最相似的向量。
SimpleVectorStore示例:
from llama_index.core.vector_stores import SimpleVectorStore
from sentence_transformers import SentenceTransformer
from llama_index.core.vector_stores import VectorStoreQuery
# 初始化SimpleVectorStore
vector_store = SimpleVectorStore()
# 加载预训练模型 pip install sentence-transformers
model = SentenceTransformer(model_name_or_path="./models/embeddings/text2vec-base-chinese-paraphrase", # 使用本地路径
cache_folder="./models/embeddings")
# 创建一些示例文本
texts = [
"这是一篇关于机器学习的文章。",
"深度学习是机器学习的一个子领域。",
"自然语言处理涉及计算机与人类语言之间的交互。"
]
# 创建一个字典来存储 doc 对象,键为 doc_id,值为 doc
doc_dict = {}
# 遍历数组生成 Document 并添加到 vector_store 中
for text in texts:
# 每个文档都有一个文本和一个向量表示
doc = Document(text=text, embedding=model.encode(text))
print(f"添加文档:{doc.text}, id: {doc.doc_id}")
vector_store.add([doc])
# 将 doc 对象添加到字典中
doc_dict[doc.doc_id] = doc
# 查询存储中的文档
queryKey = "深度学习是什么?"
query_vector = model.encode(queryKey)
# 创建查询对象
query = VectorStoreQuery(
query_embedding=[query_vector]
)
results = vector_store.query(query)
# 遍历结果中的ids,与doc_dict中的doc_id匹配,有数据则打印doc.text
for result_id in results.ids:
doc = doc_dict.get(result_id)
if doc:
print(f"查询结果:文档ID: {result_id}, 文档内容: {doc.text}")
else:
print(f"未找到对应的文档, id: {result_id}")
4.2、索引
在LlamaIndex中,索引(Index)扮演着至关重要的角色,它是实现高效数据查询和检索的关键组件。官方文档
在此主要介绍向量存储索引:其作用是将文本数据转换为向量表示,并构建一个数据结构,使得可以快速地根据向量相似度进行搜索和检索。
作用:
- 数据转换:索引首先将原始文本数据转换为向量表示。这通常是通过使用预训练的语言模型来实现的,这些模型可以将文本映射到高维向量空间中,使得语义相似的文本在向量空间中距离相近。
- 构建索引结构:一旦文本数据被转换为向量,索引会构建一个数据结构(如倒排索引或向量索引)来存储这些向量。这个结构允许快速地查找与给定查询向量最相似的向量,从而实现高效的搜索和检索。
- 加速查询:通过索引,LlamaIndex可以在大规模的文本数据中快速找到与查询相关的文档或段落。这对于构建基于大型语言模型的应用程序(如问答系统、信息检索系统等)至关重要,因为它可以显著减少查询响应时间。
与向量数据库的关联:
- 存储向量数据:向量数据库提供了高效的存储机制来存储大量的向量数据。LlamaIndex可以将其索引结构存储在向量数据库中,以便在需要时快速加载和查询。
- 查询优化:向量数据库通常具有优化的查询算法和索引结构,以支持快速的向量相似度搜索。LlamaIndex可以利用这些特性来加速其查询过程,从而提高整个系统的性能。
使用向量存储的最简单方法是加载一组文档,并使用 from_documents 从这些文档构建索引:
# Load documents and build index
documents = SimpleDirectoryReader(
"../../examples/data/paul_graham"
).load_data()
index = VectorStoreIndex.from_documents(documents)
如上面示例,默认情况下VectorStoreIndex 将所有内容存储在内存中。
如下是一个完整的通过documents创建索引并检索的示例(如果要在本地执行,需要参考另一篇文章,在本地搭建Ollama环境):
from llama_index.embeddings.ollama import OllamaEmbedding
# 创建一些示例文本
texts = [
"这是一篇关于机器学习的文章。",
"深度学习是机器学习的一个子领域。",
"自然语言处理涉及计算机与人类语言之间的交互。"
]
# 将示例文本转换为Document对象
documents = [Document(text=text) for text in texts]
# 创建Settings实例并指定本地Ollama模型作为向量(Embedding)模型
Settings.embed_model = OllamaEmbedding(
model_name="llama3.1",
base_url="http://localhost:11434",
ollama_additional_kwargs={"mirostat": 0},
)
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 获取检索器(retriever)
vector_retriever = index.as_retriever(
similarity_top_k=2 # 返回2个结果
)
# 检索存储中的文档
results = vector_retriever.retrieve("深度学习是什么?")
# 打印查询结果
print(results)
上面示例中,向量检索sa_retriever返回的是VectorIndexRetriever的实例。
LlamaIndex也支持很多向量数据库,可以通过StorageContext配置Index把数据存储到向量数据库中。官网也有介绍,在此就不扩展了。
4.3、检索器
检索器负责在给定用户查询(或聊天消息)的情况下获取最相关的上下文。它可以基于索引构建,也可以独立定义。它是查询引擎(和聊天引擎)中用于检索相关上下文的关键构建模块。
LlamaIndex 除了向量检索之外还内置了其它丰富的检索机制,例如:
- 关键字检索
- RAG-Fusion 融合查询
- QueryFusionRetriever:用于在多个子检索器(sub-retrievers)中执行查询融合(query fusion)。查询融合允许在多个不同的检索器中执行相同的查询,并将结果合并以提供更全面和准确的答案。官方示例
- 还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
五、查询引擎
可以通过从索引构建并配置查询引擎。你可以组合多个查询引擎以实现更高级的功能。
单轮回复示例:
response = query_engine.query("Who is Paul Graham.")
流式输出示例:
streaming_response = query_engine.query("Who is Paul Graham.")
streaming_response.print_response_stream()
手动生成查询引擎:
你可以实现一个自定义的查询引擎。只需继承CustomQueryEngine类,定义任何你想要的属性(类似于定义一个Pydantic类),并实现一个custom_query函数,该函数返回一个Response对象或者一个字符串。
示例:
from llama_index.core.retrievers import BaseRetriever
from llama_index.core import get_response_synthesizer
from llama_index.core.response_synthesizers import BaseSynthesizer
class RAGQueryEngine(CustomQueryEngine):
"""RAG Query Engine."""
retriever: BaseRetriever
response_synthesizer: BaseSynthesizer
def custom_query(self, query_str: str):
nodes = self.retriever.retrieve(query_str)
response_obj = self.response_synthesizer.synthesize(query_str, nodes)
return response_obj
除了单轮对话的QueryEngine之外也有多轮对话的Chat Engine,可查阅官网文档
六、提示词
LlamaIndex使用一组默认的提示模板,这些模板开箱即用效果很好,需要可以去官方GitHub地址借鉴。用户也可以根据上面的提示模板来进一步定制框架的行为。
详细可查看LlamaIndex的提示词文档介绍,下面仅列出一些简单实用。
6.1、PromptTemplate定义提示词模板
PromptTemplate的用法与Python的format函数类似,如下示例:
qa_template = PromptTemplate("写一个关于{topic}的笑话")
# you can create text prompt (for completion API)
prompt = qa_template.format(topic="小明")
print(prompt)
# or easily convert to message prompts (for chat API)
messages = qa_template.format_messages(topic="小明")
print(messages)
6.2、多轮消息模板
也可以通过ChatPromptTemplate为聊天消息定义模板
from llama_index.core.llms import ChatMessage, MessageRole
message_templates = [
ChatMessage(content="You are an expert system.", role=MessageRole.SYSTEM),
ChatMessage(
content="Generate a short story about {topic}",
role=MessageRole.USER,
),
]
chat_template = ChatPromptTemplate(message_templates=message_templates)
# you can create message prompts (for chat API)
messages = chat_template.format_messages(topic=...)
print(messages)
# or easily convert to text prompt (for completion API)
prompt = chat_template.format(topic=...)
print(prompt)
七、大模型配置
选择合适的大型语言模型(LLM)是构建任何基于数据的LLM应用程序时需要考虑的首要步骤之一。
LlamaIndex构件了核心组件LLM,它可以作为独立模块使用,也可以插入到其他核心LlamaIndex模块(索引、检索器、查询引擎)中。
LlamaIndex在响应合成步骤(例如,检索之后)期间总是会使用LLM。根据所使用的索引类型,LLM在索引构建、插入和查询遍历期间也可能会被使用。
LlamaIndex为定义LLM模块提供了一个统一的接口,无论是来自OpenAI、Hugging Face还是LangChain的,这样您就无需自己编写定义LLM接口的样板代码。此接口包括以下内容(下面有更多详细信息):
- 支持文本补全和聊天端点
- 支持流式和非流式端点
- 支持同步和异步端点
LlamaIndex支持的大模型很多(官方文档),在此以Ollama为例,简单几行代码就可以调用Ollama(Ollama本地安装可以查看另一篇文章):
# 需要执行依赖安装:pip install llama-index-llms-ollama
llm = Ollama(model="llama3.1:latest", request_timeout=120.0)
resp = llm.complete("“小明”扩句")
print(resp)
定制底层LLM可以如下示例创建LLM实例,传入查询引擎中。
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
# 创建一些示例文本
texts = [
"这是一篇关于机器学习的文章。",
"深度学习是机器学习的一个子领域。",
"自然语言处理涉及计算机与人类语言之间的交互。"
]
# 将示例文本转换为Document对象
documents = [Document(text=text) for text in texts]
# 创建Settings实例并指定本地Ollama模型作为向量(Embedding)模型
Settings.embed_model = OllamaEmbedding(
model_name="llama3.1",
base_url="http://localhost:11434",
ollama_additional_kwargs={"mirostat": 0},
)
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 创建LLM实例
llm = Ollama(model="llama3.1:latest", request_timeout=120.0)
# 获取查询引擎
query_engine = index.as_query_engine(
similarity_top_k=2 # 返回2个结果
, llm = llm
)
# 查询本地的Ollama模型
results = query_engine.query("深度学习是什么?")
# 打印查询结果
print(results)
也可以通过Settings.llm设置全局语言模型,如下:
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
# 创建一些示例文本
texts = [
"这是一篇关于机器学习的文章。",
"深度学习是机器学习的一个子领域。",
"自然语言处理涉及计算机与人类语言之间的交互。"
]
# 将示例文本转换为Document对象
documents = [Document(text=text) for text in texts]
# 创建Settings实例并指定本地Ollama模型作为向量(Embedding)模型
Settings.embed_model = OllamaEmbedding(
model_name="llama3.1",
base_url="http://localhost:11434",
ollama_additional_kwargs={"mirostat": 0},
)
# 创建LLM实例并设置为全局使用的语言模型
Settings.llm = Ollama(model="llama3.1:latest", request_timeout=120.0)
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 获取查询引擎
query_engine = index.as_query_engine(
similarity_top_k=2 # 返回2个结果
)
# 查询本地的Ollama模型
results = query_engine.query("深度学习是什么?")
# 打印查询结果
print(results)
八、更多功能
LlamaIndex还有很多功能,并且因为目前版本更新迭代较快,具体还是要以官方为准,多去官网查看。
如下更多功能就不进行介绍,可以自行查看官网:
- 工作流:https://docs.llamaindex.ai/en/stable/module_guides/workflow/
- 智能体(Agent)开发框架:https://docs.llamaindex.ai/en/stable/module_guides/deploying/agents/
- RAG 的评测:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/
- 过程监控:https://docs.llamaindex.ai/en/stable/module_guides/observability/
全部评论