cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
AI大模型系列:(一)大模型领域基本概念介绍
当今时代,AI的浪潮滚滚而来,大势所趋不可阻挡。AI已经深刻的影响到了人们生活和工作的方方面面,我们能做的就是主动去拥抱它,顺势而行。
本文是我的AI大模型系列的第一篇,主要内容有:1、对大模型的一些基本概念做个简单介绍;2、简单介绍AI大模型应用开发所需要了解的技术栈;希望本文能对您有一定的帮助。
一、大模型介绍
1.1、建立概念
AGI(Artificial General Intelligence):即通用人工智能。希望AI能够拥有全面广泛的能力,可以解决各种复杂问题,而不是只能局限于特定领域。
大模型,全称为 “大语言模型”(Large Language Model,缩写 LLM),是基于深度学习技术构建的语言处理模型。它通过在海量文本数据上进行训练,学习到丰富的语言知识和语义理解能力,能够生成连贯、有逻辑的文本内容,实现多种自然语言处理任务。
对于 AI 的界定:
- 当前较为普遍的观点是:基于机器学习、神经网络技术构建的系统属于 AI 范畴。机器学习让机器通过数据学习模式和规律,神经网络则模拟人类大脑神经元结构进行信息处理和学习;相比之下,单纯基于规则、搜索的系统,由于缺乏自主学习和适应性,通常不被视为 AI。
与 AI 的交互:
- “用人思维” 是一种有效的方式。“机器思维” 下,机器功能取决于预先设定和开发的内容;“用人思维” 则将 AI 视为有能力反馈的个体,当给予任务时,它会基于自身的训练和算法给出回应,回应质量有差异,可能带来意想不到的结果。
下面介绍一些市面上优秀的大模型和对话产品:
| 国家 | 公司 | 对话产品 | 旗舰大模型 | 网址 |
| 美国 | OpenAI | ChatGPT | GPT | https://chatgpt.com/ |
| 美国 | Microsoft | Copilot | GPT | https://copilot.microsoft.com/ |
| 美国 | Gemini | Gemini | https://gemini.google.com/ | |
| 美国 | Anthropic | Claude | Claude | https://claude.ai/ |
| 中国 | 百度 | 文心一言 | 文心 | https://yiyan.baidu.com/ |
| 中国 | 阿里云 | 通义千问 | 通义千问 | https://tongyi.aliyun.com/qianwen |
| 中国 | 智谱 AI | 智谱清言 | GLM | https://chatglm.cn/ |
| 中国 | 月之暗面 | Kimi Chat | Moonshot | https://kimi.moonshot.cn/ |
| 中国 | MiniMax | 星野 | abab | https://www.xingyeai.com/ |
| 中国 | 深度探索 | deepseek | DeepSeek | https://chat.deepseek.com/ |
1.2、大模型原理简单介绍
训练和推理是大模型工作的两个核心过程,用人类比,训练就是学,推理就是用(引自孙志岗老师)。下面以以 Transformer 架构为例进行介绍。
训练阶段:
- 大模型会 “阅读” 海量文本数据,这一过程涉及机器学习技术。
- 模型对文本进行处理,把文本分割成一个个 token。
- 训练过程中,模型会统计不同 token 同时出现的概率,并将这些信息存储到 “神经网络” 文件中,这些存储的数据就是 “参数”,也被称为 “权重” 。
- 随着训练数据量的增加和训练的深入,模型逐渐学习到丰富的语言知识和语义关系。
推理阶段:
- 用户输入问题会被拆分为若干 token。
- 推理程序加载大模型,模型根据已学习到的知识和概率信息,计算出下一个出现概率最高的 token。
- 生成的 token 与上文结合,继续生成下一个 token,如此循环,逐步生成连贯的文本内容。
Token 是什么?
- 可能是英文单词、单词片段、中文词、汉字或汉字部分。
- 可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至三分之一个汉字。
- 不同的大模型可能有自己的一套tokenizer分词组件,通过不同的分词算法,它能将各种文本精准切分成合适的 token。
为什么分词?
- 可以通过英文的词根和中文的偏旁部首这方面理解,不仅要大模型懂词的含义,还得要他们懂得词根、偏旁的含义。
- 当然分词可能不会仅分到词根和偏旁部首,根据情况可能维度会更细。
- 分词算法要去平衡语义与计算的效率,尽可能的提示模型的语义理解能力。
当前的AI大模型架构有如下:
|
架构 |
设计者 |
特点 |
链接 |
|
Transformer |
|
最流行,几乎所有大模型都用它 |
|
|
RWKV |
PENG Bo |
可并行训练,推理性能极佳,适合在端侧使用 |
|
|
Mamba |
CMU & Princeton |
性能更佳,尤其适合长文本生成 |
|
|
Test-Time Training (TTT) |
Stanford, UC San Diego, UC Berkeley & Meta AI |
速度更快,长上下文更佳 |
Transformer 架构目前是人工智能领域最广泛流行的架构,目前只有 transformer 被证明了符合 scaling-law。
二、大模型应用架构
大模型技术主要分为两个部分:训练基础大模型和建造大模型应用。
- 训练基础大模型需要深厚的技术积累和庞大的计算资源支持,全球范围内仅有少数专业人员从事;
- 而建造大模型应用则具有更广泛的参与度,几乎所有技术人员甚至普通用户都可以参与其中,且应用技术具有门槛低、天花板高的特点。
2.1、产品架构
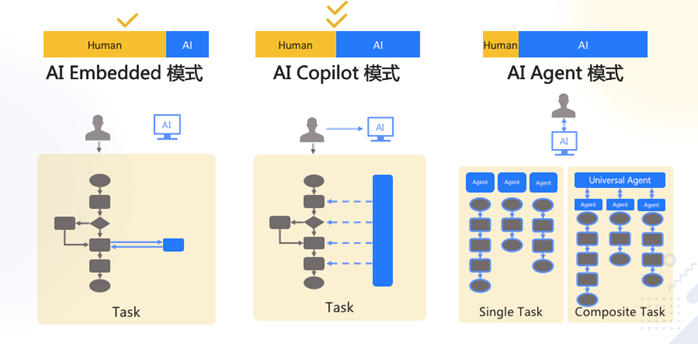
图片取自孙志岗老师的课程。
AI Embedded:简单的说,就是我们生活、工作或者某个产品的某一部分接入AI大模型,让其更智能,更高效。
AI Copilot:即对某一个工作流进行提效,形成一个产品。
Ai Agent:在今年已经逐渐从概念走向广泛应用,智能体的概念,通过Agent自身的推理和决策能力,自主调用各种软件,自动规划执行,得到用户想要的结果。
多 Agent 工作流:
- 模仿人做事,将业务拆成工作流(workflow、SOP、pipeline)。
- 每个 Agent 负责一个工作流节点。
2.2、AI应用的技术架构
- 纯 Prompt(提示):Prompt 是与大模型交互的重要接口,就像人与人对话一样,用户输入一段文本(Prompt),大模型根据输入生成相应的回复。用户可以通过精心设计 Prompt,引导大模型输出符合需求的内容。
- Agent + Function Calling:Agent 具备主动提出需求的能力,Function Calling 则允许 Agent 要求执行特定的函数。比如,当用户询问 “我明天去深圳玩,要带伞吗?” 时,Agent 会先让用户查看天气预报,获取相关信息后再结合自身知识,回答用户是否需要带伞。
- RAG(Retrieval-Augmented Generation):包括 Embeddings、向量数据库和向量搜索三个关键部分。Embeddings 将文字转换为便于计算相似度的编码(向量),向量数据库用于存储这些向量,方便后续查找。向量搜索则根据输入向量,从数据库中找到最相似的向量。例如在考试场景中,考生看到题目后到书中查找相关内容,再结合题目要求组成答案,之后可能会忘记查找的内容,RAG 技术与之类似。详细介绍可阅读《AI 大模型系列:(六)检索增强生成模型 (RAG) 和文本向量 (Embeddings) 入门》。
- Fine-tuning(精调 / 微调):就像学生针对考试内容进行有针对性的学习,长期记忆并灵活运用知识。通过对大模型进行精调,可以使其更适应特定任务或领域,提高模型在特定场景下的性能表现。
如何选择技术路线?
面对一个需求,如何选择技术方案?下面是个不严谨但常用思路。
其中最容易被忽略的,是准备测试数据
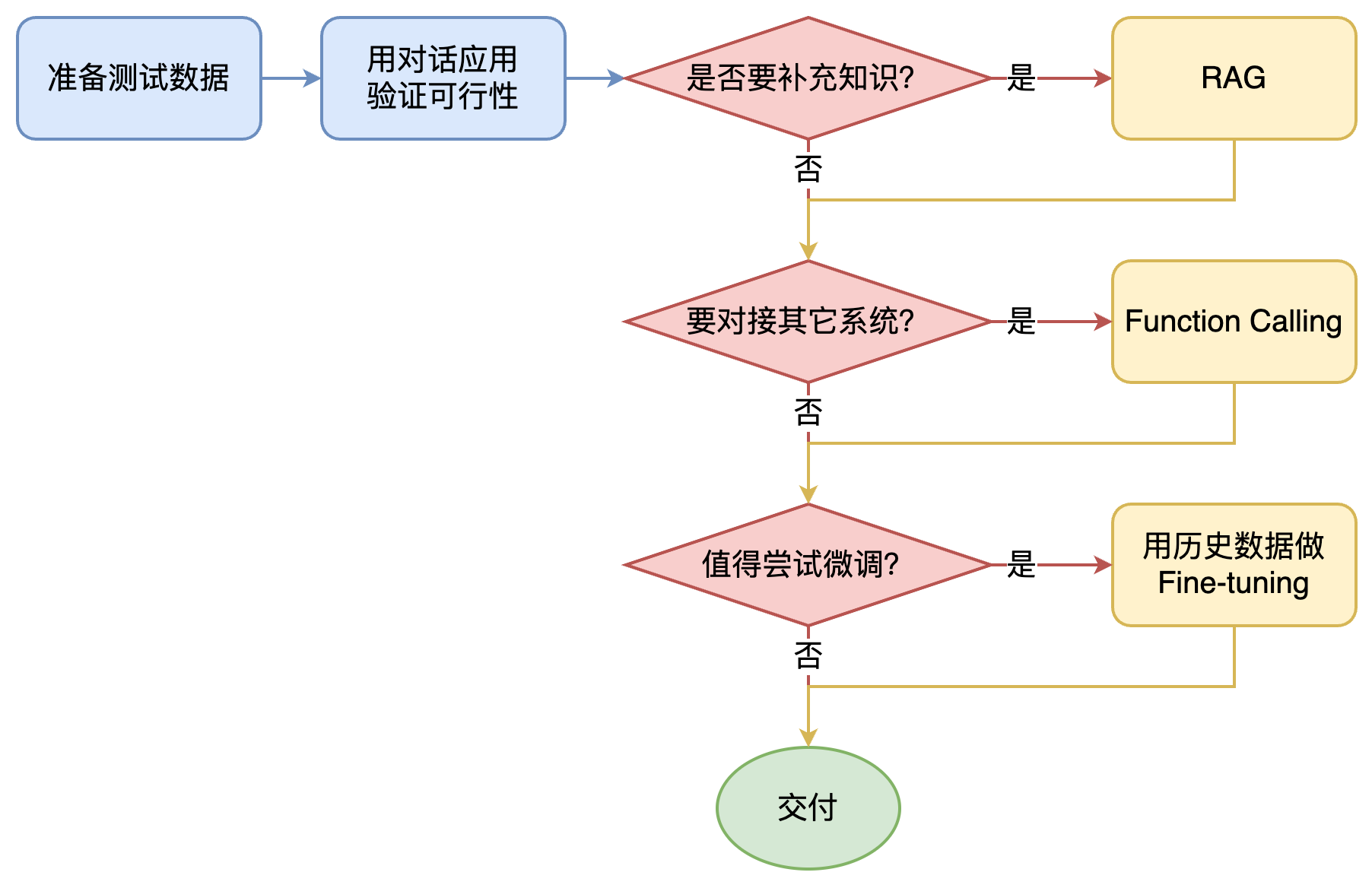
值得尝试 Fine-tuning 的情况:
- 提高大模型的稳定性
- 用户量大,降低推理成本的意义很大
- 提高大模型的生成速度
- 需要私有部署
基础模型选型:
合规和安全是首要考量因素,如下列出哪些场景适合哪种大模型:
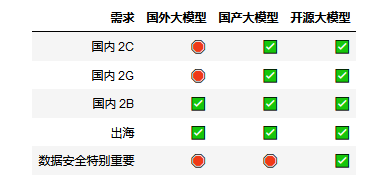
然后用测试数据,在可以选择的模型里,做测试,找出最优。
AI落地场景的思路:
- 从最熟悉的领域入手
- 让 AI 学最厉害员工的能力,再让 ta 辅助其他员工,实现降本增效
- 尽量找能用语言描述的任务
- 别求大而全。将任务拆解,先解决小任务、小场景
三、附录
内容引自孙志岗老师的AI 大模型系列课程:https://agiclass.ai/
Hugging Face:一个开源的机器学习平台,专注于自然语言处理(NLP)和人工智能(AI)。其官方网址为:https://huggingface.co。
- 提供开放获取的各种大模型(如llama系列、qwen系列、OpenGVLabIntern系列、stable diffusion系列等)的权重以及复现代码。
- 已共享超过100,000个预训练模型和10,000个数据集,成为机器学习界的重要开源资源。
- 通过提供丰富的资源和强大的工具,Hugging Face降低了机器学习的门槛,使得更多的开发者能够轻松地参与到AI项目中来。
全部评论