cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
AI大模型系列:(六)检索增强生成模型(RAG)和文本向量入门
本篇文章,主要让读者对RAG和Embeddings做一个初步的了解。
一、 检索增强生成模型
RAG(Retrieval Augmented Generation)顾名思义,通过检索的方法来增强生成模型的能力。
为什么要运用这项技术?
由于LLM固有的局限性:
- LLM 的知识不是实时的
- LLM 可能不知道你私有的领域/业务知识
因此需要通过RAG来对大模型进行增强, 显著提高生成文本的质量和准确性。
另一个原因是训练大模型所耗费的成本和资源更大。
1.1、 大语言模型开源框架
先简单介绍2个LLM开源框架,其中也集成了RAG的功能。
LlamaIndex,官网:https://www.llamaindex.ai/
优势:
- 高效检索:专注构建和查询知识库,利用PageWise Index等技术实现快速文档检索。
- 易用性高:提供标准化流程,详细文档和示例代码,初学者易上手。
- 灵活数据源:支持结构化、半结构化、非结构化数据,适用于多种数据格式。
适用场景:适用于需快速构建知识库、高效检索的场景。
LangChain,中文官网:https://www.langchain.com.cn/
优势:
- 高度定制:模块化设计,自由组合不同模块,满足特定需求。
- 广泛集成:支持多种数据存储后端,与多种工具广泛集成。
- 记忆管理:保留先前交互信息,实现上下文感知对话。
适用场景:适合需高度定制、复杂自然语言处理(NLP)应用的场景。
1.2、RAG系统基本流程介绍
如果需要自己开发一个RAG,该如何做?
本文只是对RAG系统的基本流程进行分析,用于入门了解。手写RAG系统,可以参考另一篇文章:《AI大模型系列:(七)实战,手写一个RAG系统》
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 用户调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
1.2.1、 文档加载
需要对原始数据进行如下处理,获得想要的数据:
- 数据预处理:收集并预处理各种数据源,如PDF、网页等,将其转换为统一的文档格式,便于后续处理。
- 文档分割:对长文档进行合理分段,避免信息过多或过少,同时支持多层次和语义分割,确保信息连贯。
- 摘要生成:为每块内容生成简短摘要,方便用户快速理解文档内容。
- 合理的重叠度设置
1.2.2、 检索
市面上已经有很多成熟的检索引擎,没必要重复造轮子,在此介绍几种流行的全文检索引擎:
Elasticsearch(应用最广泛,官网:https://www.elastic.co/):
- 优势:Elasticsearch是一个功能强大、易于使用的全文检索引擎,支持分布式搜索、实时更新和丰富的查询功能。它的RESTful API设计使得与各种编程语言的集成变得简单方便。此外,Elasticsearch还提供了强大的可视化和分析工具,使得数据分析和可视化变得更加容易。
- 劣势:Elasticsearch的配置和调优需要一定的技术水平和经验,特别是对于大规模集群的部署和管理。此外,虽然Elasticsearch在实时性和性能方面表现良好,但在某些特定场景下(如极高并发的写入操作)可能需要额外的优化措施。
Solr:
- 优势:Solr是一个高性能、可扩展的开源搜索平台,支持分布式搜索和索引复制。它基于Apache Lucene,并提供了丰富的查询功能和强大的配置选项。Solr在搜索速度和数据量处理方面表现出色,特别适用于大规模的数据搜索场景。
- 劣势:Solr的配置相对复杂,需要一定的技术水平和经验才能进行有效的调优。同时,它的实时性稍差,对于需要实时更新和查询的场景可能不太适用。
Sphinx:
- 优势:Sphinx是一个开源的全文搜索引擎,可以与MySQL、PostgreSQL等数据库以及纯文本数据源进行集成。它提供了快速、高效的索引和搜索功能,并支持多种查询语言和结果排序方式。Sphinx的轻量级设计使得它在资源消耗和性能方面表现良好。
- 劣势:相比Elasticsearch,Sphinx的功能相对较少,特别是在分布式搜索和实时性方面稍显不足。此外,它的配置和调优也需要一定的技术经验。
关键字检索的优缺点:
- 缺点:同一个语义,用词不同,可能导致检索不到有效的结果。
- 优点:语义明确,适合对专业性强的内容进行检索。如包含医学术语的问题。
要补足关键字检索的缺点,就需要用到另一个技术:向量检索
二、向量检索
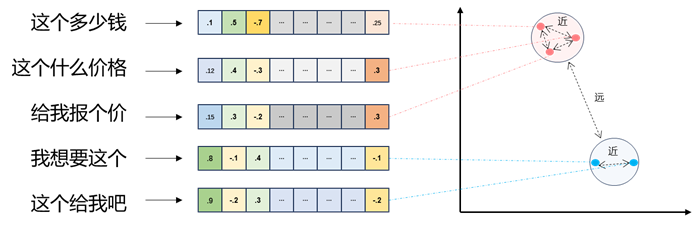
2.1、文本向量
- 将文本转成一组维浮点数,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
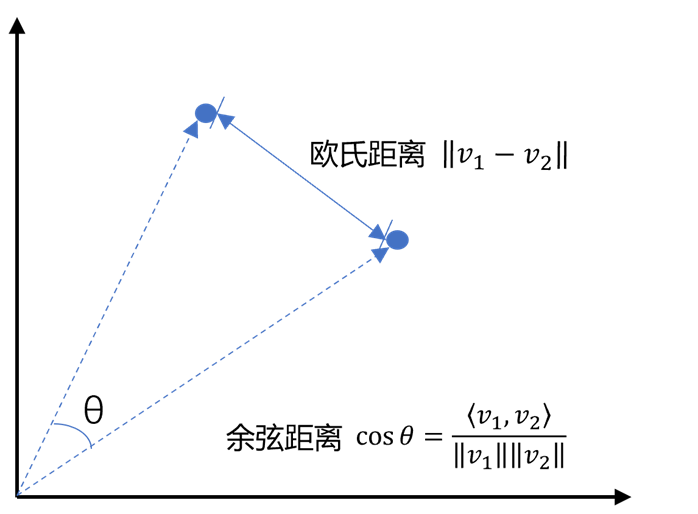
2.2、向量间的相似度计算
- 欧氏距离:其实就是计算两点之间的直线距离。
- 余弦距离:其实就是计算两点到原点之间的夹角。
2.3、Embedding模型选择
在RAG中,我们要通过Embedding模型把文字、图片等转换为一个向量表示,我们的知识库数据通过上文的加载切割后,可以把分割后的文字通过Embedding模型转换为向量,与原始数据一起存入向量数据库中,然后用户提出的问题也会用同一个Embedding模型转换为向量,去向量数据库中查询出语义相近的数据。
注意:RAG中知识库的向量化和查询语句的向量化得用同一个Embedding模型。
特性:
- 语义压缩:将复杂对象(如单词、句子、图片)转化为稠密向量(如300维),捕捉其内在的语义或特征。
- 相似度量化:在向量空间中,语义相似的对象距离更近(例如“猫”和“狗”的向量余弦相似度较高)。
HuggingFace中有Embedding榜单,地址:https://huggingface.co/spaces/mteb/leaderboard,(需要科学上网)
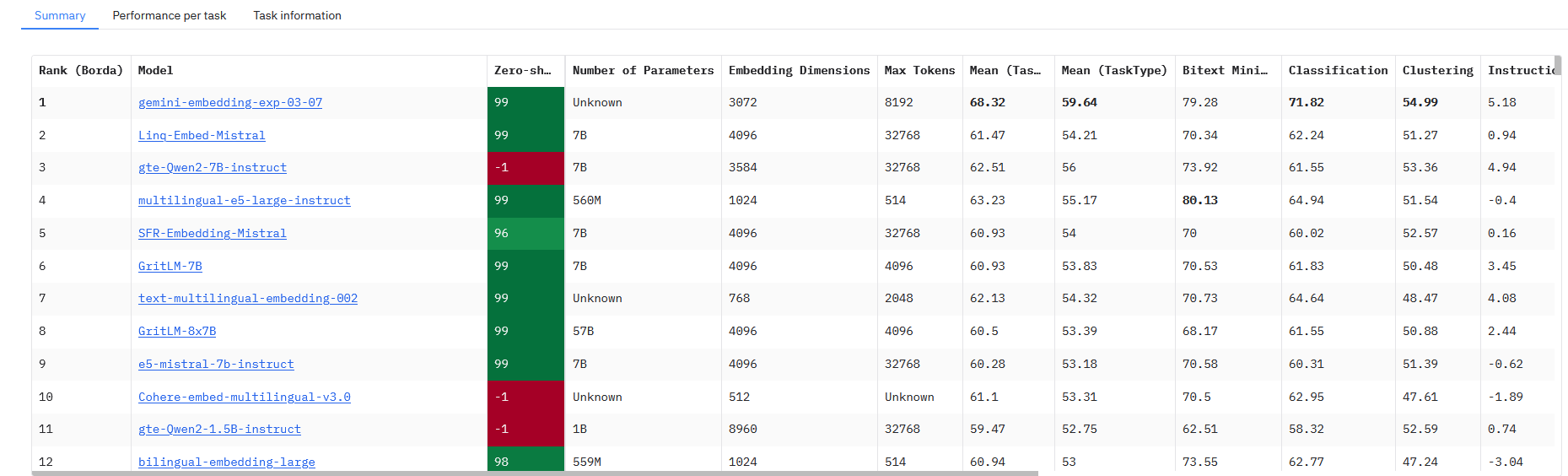
以下是针对 RAG(检索增强生成)项目 的 Embedding 模型选型推荐:
| 模型名称 | 核心优势 | 适用场景优先级 | 部署建议 |
|---|---|---|---|
| gte-Qwen2-7B-instruct | 多语言(27+)、长文本(128K tokens)、指令优化,中文任务领先,RAG专用设计 | 高优先级:多语言/中文RAG、长文档场景 | 需GPU资源,推荐阿里云或本地高性能服务器 |
| BGE-M3 | 多语言(100+)、混合检索(密集+稀疏+多向量)、开源社区支持 | 高优先级:复杂检索、跨语言场景 | 支持CPU/GPU,适合中小团队快速集成 |
| BGE系列(如bge-large) | 轻量级、中英文优化,Hugging Face生态完善 | 中优先级:中文/英文单语言RAG | 低资源需求,适合初创项目或原型验证 |
| E5 | 通用性强,Zero-shot表现稳定,训练方法创新 | 中优先级:通用检索、低标注数据场景 | 中等资源需求,适合学术研究或小规模应用 |
模型维度比较:
| 维度 | gte-Qwen2-7B | BGE-M3 | BGE-large-zh | E5 |
|---|---|---|---|---|
| 多语言支持 | 27+语言 | 100+语言 | 中英文 | 英语为主 |
| 长文本能力 | 128K tokens | 8K tokens | 512 tokens | 512 tokens |
| 中文任务表现 | 效果最好 | 优秀 | 优秀 | 一般 |
| 部署成本 | 高(需GPU) | 中 | 低 | 低 |
| 社区支持 | 中等(阿里) | 高(开源) | 高(开源) | 高(开源) |
如何根据项目需求快速匹配模型:
- 是否需要处理中文?
- 是 → gte-Qwen2-7B-instruct(最优中文性能) 或 BGE系列(轻量级替代)
- 否 → 进入下一步
- 是否跨多语言(>10种语言)?
- 是 → BGE-M3(语言覆盖最广)
- 否 → E5(英语/西欧语言优先)
- 是否需要处理超长文本(>8K tokens)?
- 是 → gte-Qwen2-7B-instruct(128K tokens)
- 否 → BGE系列/E5(性价比更高)
- 是否资源受限(GPU/算力不足)?
- 是 → BGE-small 或量化版 gte-Qwen2-7B-GGUF
- 否 → 优先选择大模型(gte-Qwen2-7B/BGE-M3)
避坑指南:
- 避免盲目追求大模型:7B级模型需至少16GB GPU显存,若无必要可选用BGE-base(参数量小10倍)。
- 长文本陷阱:过90%的RAG场景实际处理文本<2K tokens,超长文本需求需明确(如法律/医学)。
- 多语言伪需求:若业务仅涉及中英文,BGE-M3的100+语言特性可能带来冗余计算开销。
- 量化版本谨慎使用:GGUF等量化格式会损失部分精度,需测试后再上线(如gte-Qwen2-7B-q4精度下降约3%)。
2.4、向量数据库
想要高效的检索生成的向量数据,在大数据量的条件下靠for循环去检索是不现实的,就需要用到向量数据库。
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
如下是一些主流的向量数据库:
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
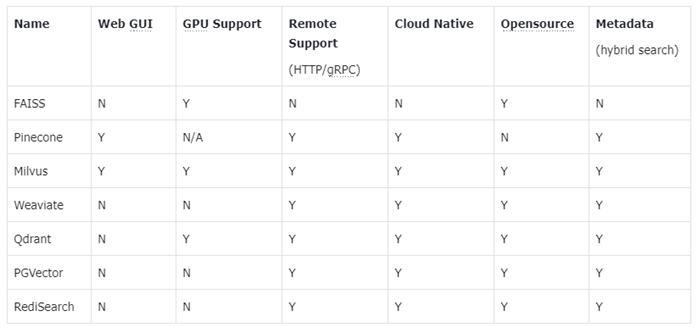
Milvus和Weaviate在功能和性能方面都还不错,传统数据库厂商的向量数据库(ElasticSearch、RediSearch)性能方面还是有差距。
2.4.1、FAISS、Milvus和Weaviate比较
|
FAISS |
Milvus |
Weaviate |
|
|
优点 |
|
|
|
|
缺点 |
|
|
|
小型项目/快速原型:推荐 FAISS。原因:部署简单、直接pip安装、使用方便、代码量少、性能够用、适合嵌入式场景
中型生产项目:推荐 Milvus。原因:功能完整、性能稳定、支持持久化、社区活跃
大型企业项目:推荐 Milvus/Weaviate。原因:支持分布式、企业级特性、可扩展性好、安全性高
三、实战中可能遇到的问题
3.1、文本分割的粒度
文本分割时可能出现如下问题:
- 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
- 问题的答案可能跨越两个片段
改进:
按一定粒度,部分重叠式的切割文本,使上下文更完整。即分割后这一段写入带上下一段内容,下一段写入带上上一段内容。
3.2、检索后的排序问题
有时候最合适的答案不一定排序在结果的最前面,向量数据库通过向量搜索是非常高效的,但是向量的大小和问题相似度不是成正比的,所以需要再给大模型去重新打分。
方案,引入一个排序模型:
- 检索时多招回一部分文本。比如排序10条,先获得100条。
- 通过一个排序模型对 query 和 document 重新打分排序。
把问题和检索回来的100条数据,以一对一的关系发给大模型,然后让大模型重新打分排序。
市面上已经有一些重新排序的服务:
- Cohere Rerank:支持多语言,https://cohere.com/rerank
- Jina Rerank:目前只支持英文,https://jina.ai/reranker/
3.3、关键字检索和向量检索各有优劣
在实际生产中,传统的关键字检索与向量检索各有优劣。
改进方案:混合检索
有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
混合检索的核心是,综合文档d在不同检索算法下的排序名次(rank),为其生成最终排序。
一个最常用的算法叫 Reciprocal Rank Fusion(RRF):
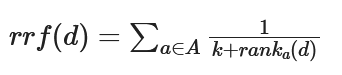
其中A表示所有使用的检索算法的集合, ranka(d)表示使用算法a检索时,文档d的排序,k是个常数用来表示敏感度,如果是0,那么文档只要有一次排在前面其生成的最终排名也在前面。
很多向量数据库都支持混合检索,比如 Weaviate、Pinecone 等。也可以根据上述原理自己实现。
3.4、通用知识的RAG
可以考虑接入搜索引擎来实现
全部评论