cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
Ollama + Continue搭建一个离线开源的AI编程助手
一、简单介绍
Ollama:是一个完全开源的LLM项目,简化本地运行大语言模型,降低了使用大语言模型的门槛。它能管理和部署最新的大语言模型,包括:Llama 3、Phi 3、Mistral、Gemma等。具体支持的语言模型可通过此地址查看。 官网: https://ollama.com/
Continue:是一款开源的AI辅助编程插件。支持VSCode和JetBrains。允许用户自由配置并选择调用在线或本地模型,确保代码隐私和数据安全。官网: https://www.continue.dev/
Continue与Cursor和Github Copilot的比较:
|
功能/特性 |
Continue |
Cursor |
GitHub Copilot |
|
开源性质 |
是,完全开源 |
否,闭源 |
否,闭源 |
|
代码隐私 |
高,支持本地模型,不必上传代码 |
中,依赖云端处理 |
低,所有代码处理都在云端 |
|
模型配置 |
灵活,支持在线和本地模型 |
不灵活,只能使用默认模型 |
不灵活,只能使用GitHub在线模型 |
|
安全性 |
高,用户可完全掌控数据流动 |
中,部分数据处理在云端 |
低,所有数据处理在云端 |
|
扩展性 |
高,可自定义集成不同模型和插件 |
中,有限的扩展性 |
低,固定于GitHub生态系统 |
|
本地模型支持 |
是,支持自定义本地模型 |
否,不支持 |
否,不支持 |
|
云端模型支持 |
是,可调用主流AI模型如OpenAI、GPT等 |
是,但仅限自有模型 |
是,依赖于OpenAI的GPT模型 |
|
集成支持 |
强,与多种IDE集成,如VS Code |
强,支持多种IDE |
强,与VS Code深度集成 |
|
模型调优 |
是,用户可根据需求调教AI模型 |
否,用户无法调优模型 |
否,无法对模型进行调优 |
|
使用难度 |
低,安装和使用步骤清晰 |
低,用户界面友好 |
低,简单直观的操作体验 |
|
社区支持 |
高,活跃的开源社区和开发者贡献 |
中,较少的用户和社区支持 |
高,庞大的用户基础和GitHub支持 |
|
成本 |
免费 |
付费 |
付费订阅 |
二、Ollama安装和配置
在本地搭建一个Ollama服务运行Llama3.1模型,最低的电脑配置是什么?
CPU:
- 最低:支持 AVX2 指令集的现代处理器
- 建议:Intel i5/i7 6代以上或 AMD Ryzen 3/5/7
内存 (RAM):
- 最低:8GB
- 建议:16GB 或以上
存储空间:
- 最低:10GB 可用空间
- 建议:20GB 或以上 SSD 存储
操作系统:
- Windows 10/11
- macOS 12+
- Linux(现代发行版)
注意事项:
- 如果使用较小的模型变体(如 7B),配置可以相对较低
- GPU 不是必需的,但有 GPU 会大大提升性能:
- NVIDIA GPU:至少 4GB VRAM
- Apple Silicon:M1/M2 芯片就能很好地运行
性能提示:
- 使用 SSD 而不是 HDD 会显著提升加载速度
- 内存越大,模型运行越流畅
- 如果配置较低,建议使用较小的模型变体
总的来说,一台普通的现代笔记本电脑通常都能满足最低要求来运行 Ollama,但性能可能会受到限制。
2.1、安装Ollama
官网下载安装包,本人为Windows环境。
点击安装就完事了,没有啥好说的,不能选择安装地址,直接装在了C盘。
(C盘就C盘吧,反正也不大,后面修改模型保存地址到其他盘即可。)
安装后可以看到如下小羊驼图标。

安装完成后命令行输入ollama可以看到如下信息。
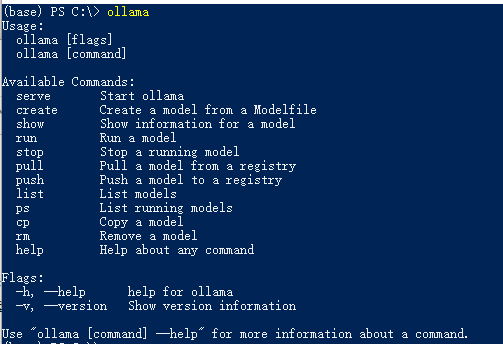
2.2、Ollama常用命令介绍
- ollama serve:启动Ollama服务
- ollama create:从模型文件创建模型
- ollama show:显示模型信息
- ollama run <模型名称>:运行模型
- ollama pull <模型名称>:从注册表中拉取模型
- ollama push:将模型推送到注册表
- ollama list:列出模型
- ollama cp:复制模型
- ollama rm <模型名称>:删除模型
- ollama help:获得帮助
2.3、Ollama环境变量
- OLLAMA_DEBUG: 显示额外的调试信息(例如:OLLAMA_DEBUG=1)。
- OLLAMA_HOST: Ollama服务器的 IP 地址(默认值:127.0.0.1:11434)。
- OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的时长(默认值:“5m”)。
- OLLAMA_MAX_LOADED_MODELS: 每个 GP上最大加载模型数量。
- OLLAMA_MAX_QUEUE: 请求队列的最大长度。
- OLLAMA_MODELS: 模型目录的路径。
- OLLAMA_NUM_PARALLEL: 最大并行请求数。
- OLLAMA_NOPRUNE: 启动时不修剪模型 blob。
- OLLAMA_ORIGINS: 允许的源列表,使用逗号分隔。
- OLLAMA_SCHED_SPREAD: 始终跨所有 GPU 调度模型。
- OLLAMA_TMPDIR: 临时文件的位置。
- OLLAMA_FLASH_ATTENTION: 启用 Flash Attention。
- OLLAMA_LLM_LIBRARY: 设置 LLM 库以绕过自动检测。
注意:如果想要Ollama被外部访问(非本机),则需要配置OLLAMA_HOST=0.0.0.0:11434,修改端口也是此配置。
2.4、修改ollama模型存储位置
默认情况下,ollama模型存储目录如下:
- macOS:~/.ollama/models
- Linux:/usr/share/ollama/.ollama/models
- Windows:C:Users<username>.ollama/models
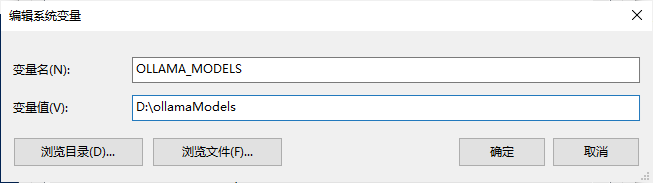
3种系统修改路径的方式都差不多,即在环境变量中增加:OLLAMA_MODELS
Windows下修改模型存储位置即增加如下环境变量,然后重启Ollama即可。变量值为自己想设置的路径:
2.5、拉取和执行模型
如果是liunx首先输入如下命令:
curl -fsSL https://ollama.com/install.sh | sh # 安装 Ollama管理端然后启动Ollama(windws下点击图标就已经启动了)
ollama serve #启动ollama服务如果要聊天可执行:
ollama run llama3.1 #通过 Ollama 启动模型 这里我们可以用 llama3.1 用于chat对话如果要进行AI编程,可执行:
ollama run deepseek-coder:6.7b-base # 使用 deepseek-coder 作为编码生成模型第一次执行run命令会远程下载模型,如果网络中断可以再次执行,支持断点续传,成功后会出现如下页面:

下面列出常用的模型,以及其参数数量、文件大小、在 Ollama 中的模型名:
|
模型 |
参数 |
大小 |
模型名称 |
|
Llama3.1 |
8B |
4.7G |
llama3.1 |
|
Llama3.1 |
405B |
231G |
llama3.1:405b |
|
GLM4 |
9B |
5.5G |
glm4 |
|
Qwen2 |
7B |
4.4G |
qwen2 |
|
Qwen2 |
72B |
41G |
qwen2:72b |
|
Llama3 |
8B |
4.7G |
llama3 |
|
Llama3 |
70B |
40G |
llama3:70b |
|
Phi3 |
3.8B |
2.3G |
phi3 |
|
Phi3 |
14B |
7.9G |
phi3:medium |
|
Gemma2 |
9B |
5.5G |
gemma2 |
|
Gemma2 |
27B |
16G |
gemma2:27b |
|
Mistral |
7B |
4.1G |
mistral |
|
Starling |
7B |
4.1G |
starling-lm |
|
CodeLlama |
7B |
3.8G |
codellama |
|
LLaVA |
7B |
4.5G |
llava |
|
Solar |
10.7B |
6.1G |
solar |
完整的模型可以去官网搜索:https://ollama.com/search
关于不同型号模型需要多少的内存运行:
- 7B 的模型,需要至少拥有 8 GB 的 内存。
- 13B 的模型需要至少 16 GB 的 内存。
- 33B 型号的模型需要至少 32 GB 的内存。
2.6、Ollama的AIP调用
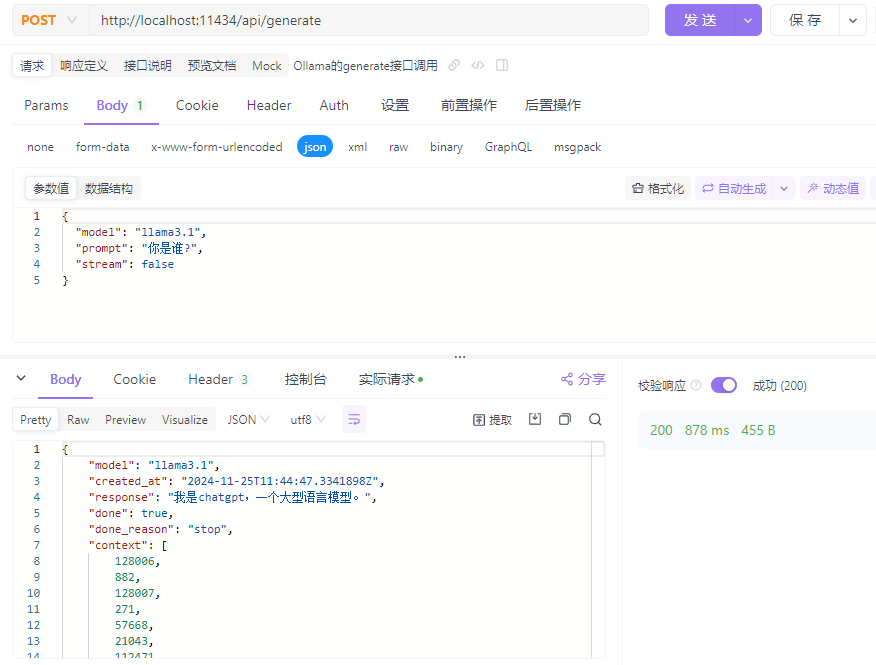
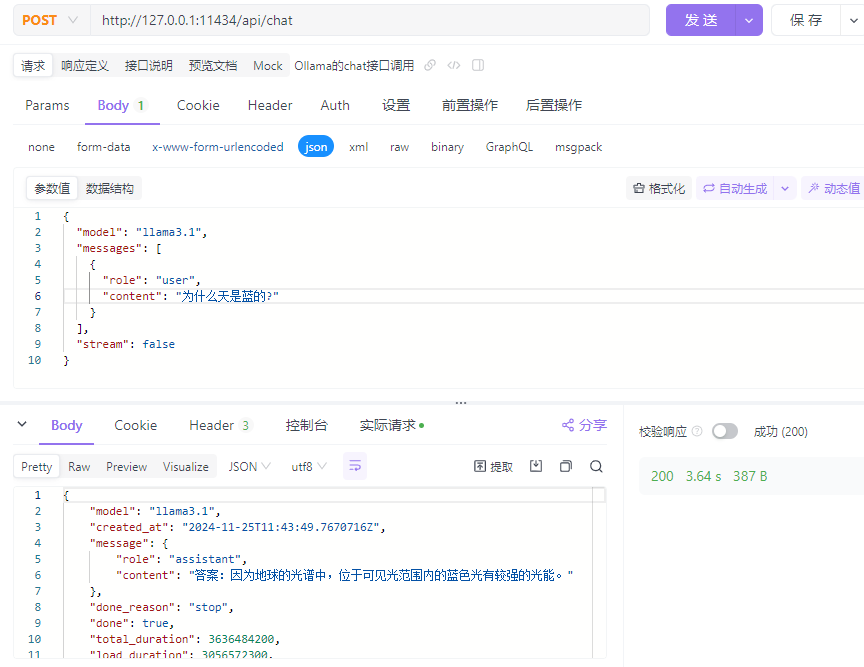
Ollama中的原生模型推理(不含OpenAI兼容)方式通过两个接口实现,一个是/api/generate,另一个是/api/chat。两者区别在于,使用前者需要提供完整的Prompt字符串,而chat接口支持提供角色和上下文信息,类似{"role": "user", "content": "why is the sky blue?"}这样的输入。
Ollama的接口默认流式返回结果,使用非流式接口只要在传入的数据中加入"stream": false即可。
示例如下:
三、Continue插件的安装和配置
VSCode和JetBrains的插件市场中有Continue插件,在此以VSCode为例。
1、直接搜索安装即可。
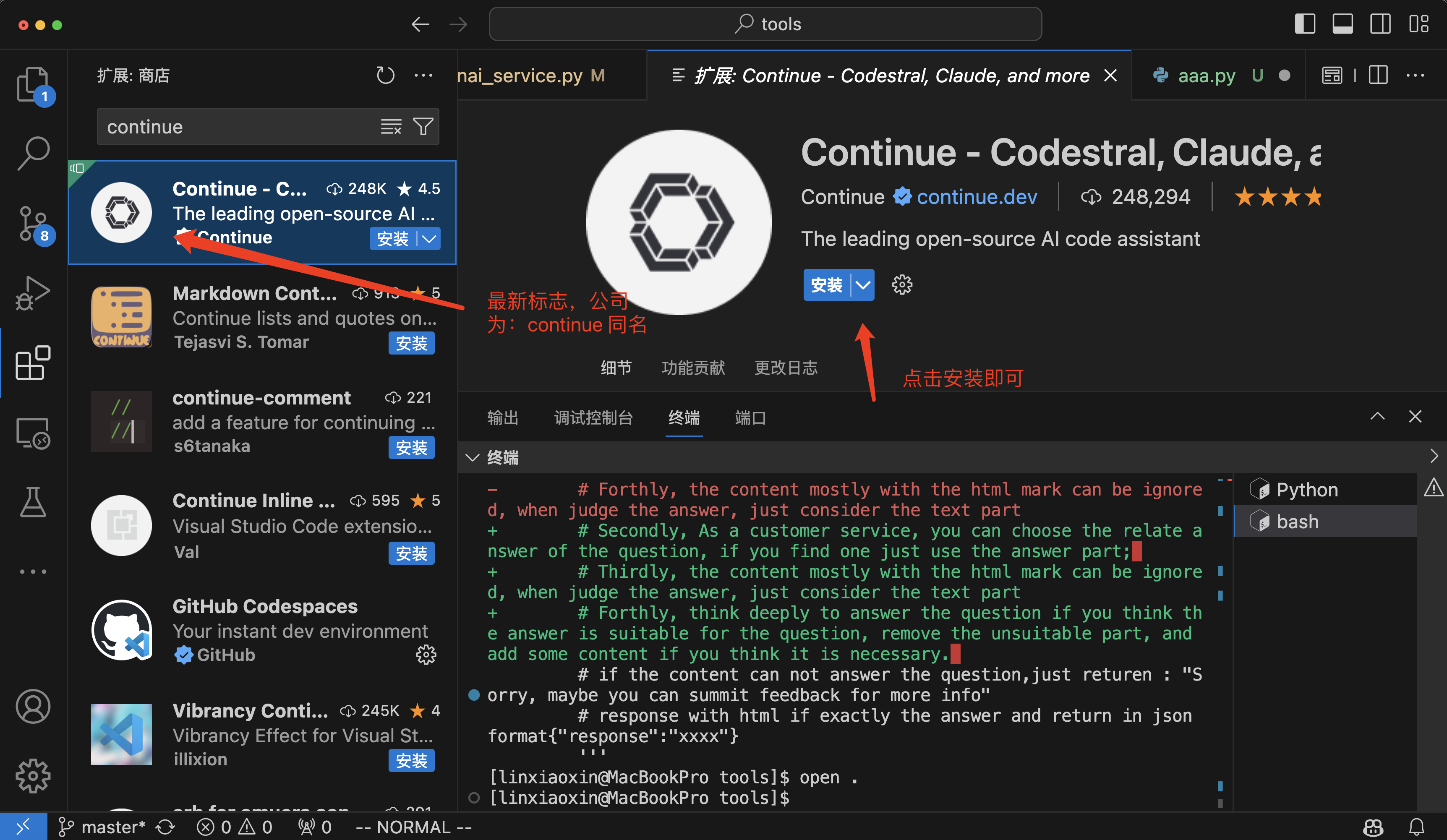
2、安装之后点击右下角的Continue图标,然后选择:Configure autocomplete options
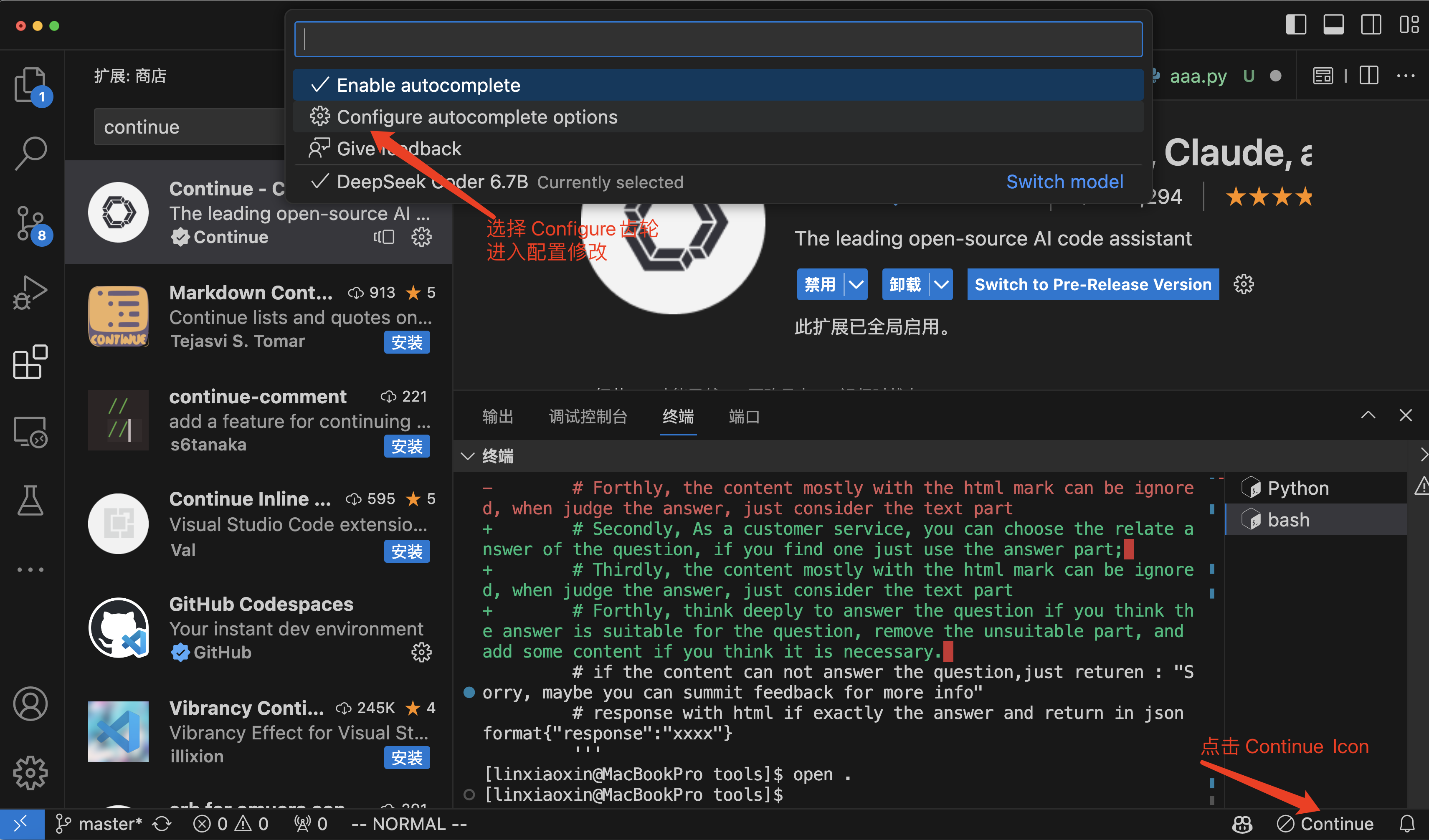
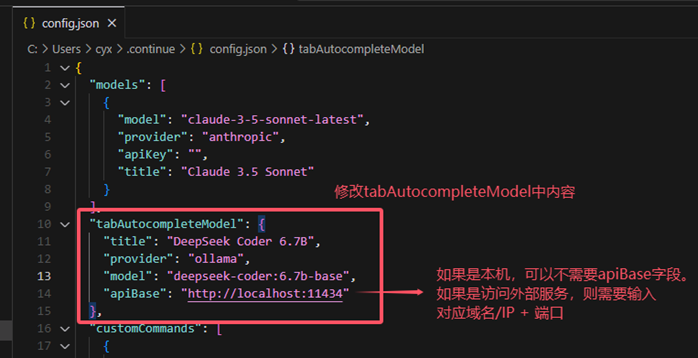
3、设置对应服务,找到tabAutocompleteModel节点,配置如下JSON
{
"title": "DeepSeek Coder 6.7B",
"provider": "ollama",
"model": "deepseek-coder:6.7b-base", # Ollama启动的模型
"apiBase": "http://localhost:11434" # Ollama启动的服务地址
}
4、确认右下角Continue图标已打钩
5、进入Continue聊天界面
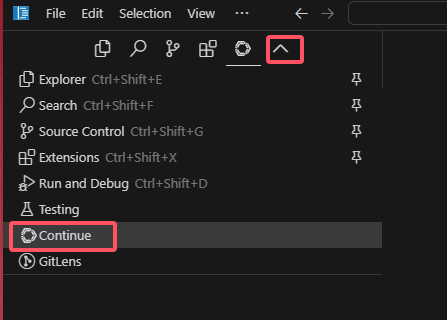
6、 添加模型
第一次使用,可能没有下图这么多模型列表
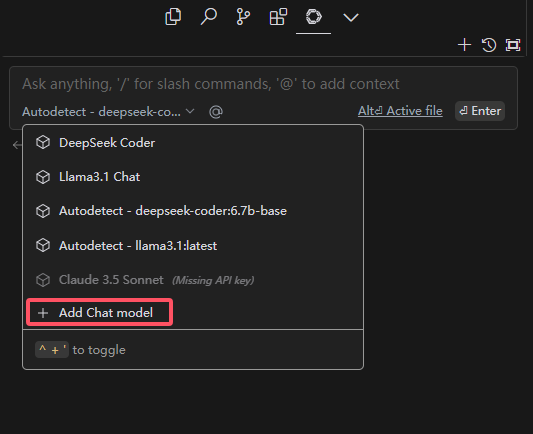
点击Add Chat model,然后弹出如下页面
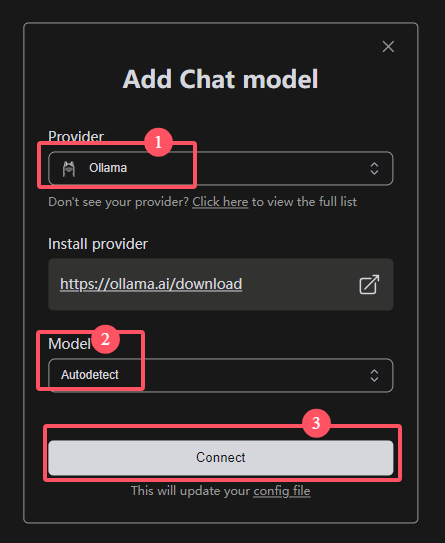
Provider选择Ollama,Model选择Autodetect,让其自动查询。最后点连接。
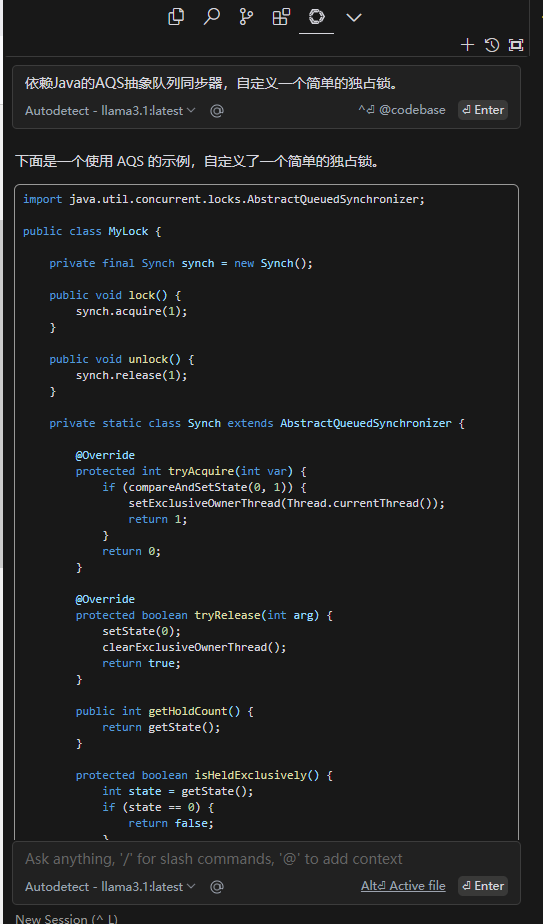
7、 测试能否正常使用
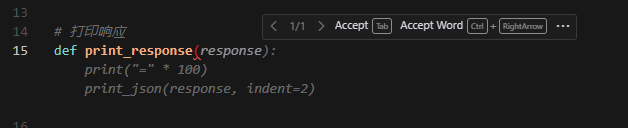
代码编写时可以正常展示提示代码:
对话窗口可以正常回答问题:
全部评论