cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
AI大模型系列:(十)Langchain介绍
LangChain 是一个用于构建大语言模型(LLM)驱动应用的开发框架,旨在帮助开发者更高效地将 LLM(如 GPT、Claude 等)与外部数据、工具及计算逻辑结合,实现复杂任务的自动化与智能化。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
- 开发:使用 LangChain 的开源组件和第三方集成来构建您的应用程序。使用 LangGraph 构建具有原生流支持和人工干预支持的有状态智能体。
- 产品化:使用 LangSmith 检查、监控和评估您的应用程序,以便您可以持续优化并放心部署。
- 部署:通过 LangGraph 平台将有状态的 LangGraph 应用程序转化为生产就绪的 API 和助手 。
LangChain的官方的各产品开源情况:
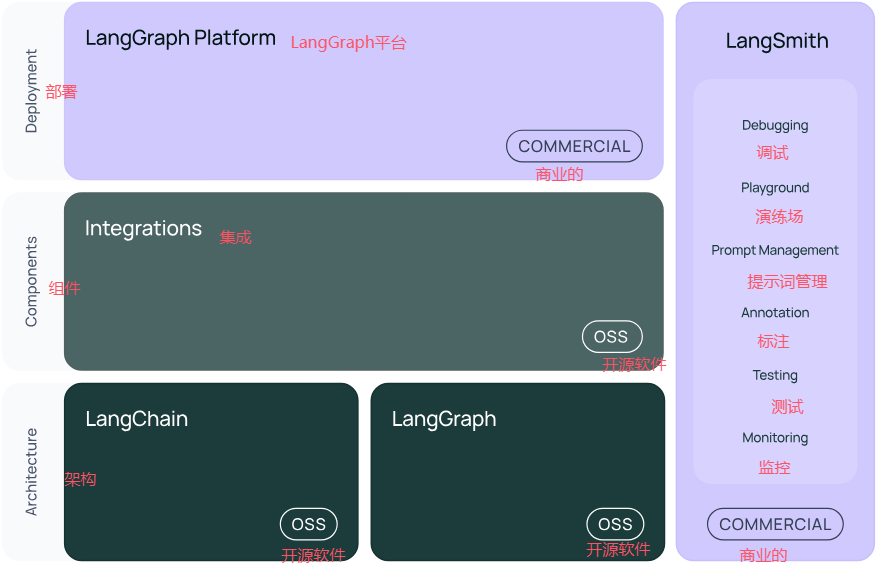
LangChain 开源框架的结构如下:
- langchain-core:聊天模型和其他组件的基础抽象。
- 集成包(例如 langchain-openai、langchain-anthropic 等):重要的集成已被拆分为轻量级包,由 LangChain 团队和集成开发者共同维护。
- langchain:构成应用程序认知架构的链、智能体和检索策略。
- langchain-community:由社区维护的第三方集成。
- langgraph:用于将 LangChain 组件组合成具有持久性、流处理和其他关键功能的生产就绪应用程序的编排框架。有关详细信息,请参阅 LangGraph 文档 。
在此我们主要介绍开源的LangChain组件,官方文档(以 Python 版为例):
- 功能模块:https://python.langchain.com/docs/introduction/
- API 文档:https://python.langchain.com/api_reference/
- 官方教程:https://python.langchain.com/docs/tutorials/
- 官方案例:https://python.langchain.com/docs/how_to/#use-cases
- 三方组件集成:https://python.langchain.com/docs/integrations/platforms/
- 调试部署等指导:https://python.langchain.com/docs/how_to/debugging/
- LangChain各个包安装指导:https://python.langchain.com/docs/how_to/installation/
- LangChain和pydantic的版本关系:https://python.langchain.com/docs/how_to/pydantic_compatibility/
一、LangChain的核心组件
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作(啥意思?别急,后面详细讲)
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
- 对话历史管理
- 对话历史的存储、加载与剪裁
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
更多LangChain组件可查看官方文档
二、模型I/O 封装
LangChain支持很多种模型(具体查看官网),它把不同的模型,统一封装成一个接口,方便更换模型而不用重构代码。同时还为监控、调试和优化使用大语言模型(LLMs)的应用程序性能提供了额外功能。
2.1、聊天模型
LangChain 拥有许多聊天模型集成,这些集成分为两种类型:
- 官方模型:您可以在 langchain-<provider>包中找到这些模型。
- 社区模型:这些模型大多由社区贡献和支持。您可以在 langchain-community 包中找到这些模型。
具体哪些是官方模型,哪些是社区模型,可以通过官方网站都有详细介绍。
LangChain 聊天模型的命名遵循一种约定,即在它们的类名前加上“Chat”前缀(例如,ChatOllama、ChatAnthropic、ChatOpenAI 等)。
2.1.1、BaseChatModel
LangChain为聊天模型定义的统一接口是BaseChatModel。由于 BaseChatModel 也实现了 Runnable(可运行)接口,因此聊天模型支持标准的流式接口、异步编程、优化批处理等功能。
BaseChatModel模型的主要方法:
- invoke:与聊天模型交互的主要方法。它以消息列表作为输入,并以消息列表作为输出。
- stream:一种可以在聊天模型生成输出时对其进行流式传输的方法。
- batch:一种可以将多个对聊天模型的请求批量处理以实现更高效处理的方法。
- bind_tools:一种可以将工具绑定到聊天模型以便在模型的执行上下文中使用的方法。
- with_structured_output:对于原生支持结构化输出的模型,这是对调用(invoke)方法的一种包装。
其他更详细的方法,可查看官方API文档
BaseChatModel提供的标准参数:
- model:指定要使用的特定AI模型的名称或标识符(例如,“gpt-3.5-turbo”或“gpt-4”)。
- temperature:控制模型输出的随机性。较高的值(例如,1.0)使响应更具创造性,而较低的值(例如,0.0)使它们更确定和专注。
- timeout:等待模型响应的最大时间(以秒为单位),在此之后将取消请求。这确保了请求不会无限期地挂起。
- max_tokens:限制响应中的总标记数(单词和标点符号)。这控制了输出的长度。
- stop:指定停止序列,指示模型何时应停止生成标记。例如,您可以使用特定的字符串来表示响应的结束。
- max_retries:系统在因网络超时或速率限制等问题导致请求失败时,重试请求的最大次数。
- api_key:与模型提供商进行身份验证所需的API密钥。这通常在您注册访问模型时发放。
- base_url:发送请求的API端点的URL。这通常由模型提供商提供,并且对于指导您的请求是必要的。
- rate_limiter:可选的BaseRateLimiter,用于避免超出速率限制而间隔请求。有关更多细节,请参阅速率限制部分。
标准参数目前仅在具有自身集成包的集成中强制执行(例如 langchain-openai、langchain-anthropic 等),在 langchain-community 中的模型上不强制执行。
聊天模型还接受特定于该集成的其他参数。要查找聊天模型支持的所有参数,请参阅该模型的相应 API 参考文档 。
2.1.2、两种消息格式
LangChain 支持两种消息格式来与聊天模型交互:
- LangChain 消息格式:LangChain 自己的消息格式,默认使用并由 LangChain 内部使用。
- OpenAI 的消息格式:OpenAI 的消息格式。
在此主要介绍下LangChain的消息格式,LangChain 提供了一种统一的消息格式,可在不同的聊天模型中使用,使用户能够在不同聊天模型之间切换,而无需担心每个模型提供商所使用的具体消息格式细节 。
LangChain 消息有五种主要的消息类型,都是继承与BaseMessage,达到统一消息格式的目的:
- SystemMessage:对应系统角色
- HumanMessage:对应用户角色
- AIMessage:对应助手角色
- AIMessageChunk:对应助手角色,用于流式响应
- ToolMessage:对应工具角色
更详细的LangChain消息内容可查看官网的Messages指南
2.1.3、代码示例
基于本地的Ollama进行测试,如果本地没部署Ollama的可参考我的另一篇文章
from langchain.schema import (
HumanMessage, # 等价于OpenAI接口中的user role
SystemMessage # 等价于OpenAI接口中的system role
)
llm = ChatOllama(
model="llama3.1",
temperature=0,
base_url="http://127.0.0.1:11434",
client_kwargs={"timeout": 60},
)
# openAI的消息格式示例
messages = [
(
"system",
"你是一个将英语翻译成中文的有用助手。翻译用户的句子 。",
),
("human", "I love programming."),
]
ai_result = llm.invoke(messages) # 返回的是AIMessage类型
print(ai_result.content)
# langchain的消息格式示例
messages = [
SystemMessage(content="你是一个将英语翻译成中文的有用助手。翻译用户的句子 。"),
HumanMessage(content="I love programming.")
]
ai_result = llm.invoke(messages) # 返回的是AIMessage类型
print(ai_result.content)
其它关于聊天模型的工具调用、多模态、结构化输出等,请自行查看官方文档。
2.2、提示词模板
提示模板有助于将用户输入和参数转化为语言模型的指令。这可用于引导模型的回复,帮助其理解上下文并生成相关且连贯的基于语言的输出。
提示模板以一个字典作为输入,其中每个键代表提示模板中要填充的一个变量。
提示模板输出一个提示值(PromptValue),这个提示值可以传递给一个大型语言模型(LLM)或聊天模型,并且还可以被转换为字符串或消息列表。
下面介绍两种类型的提示词模板:
- 字符串提示模板(PromptTemplate):用于格式化单个字符串,通常用于较简单的文字输入。
- 聊天提示模板(ChatPromptTemplates):这些提示模板用于格式化聊天消息。
消息占位符(MessagesPlaceholder):在ChatPromptTemplate中,如果我们希望用户传入一个消息列表,并将其插入到特定位置,该怎么做呢?这时候就可以使用消息占位符。
示例:
from langchain.prompts.chat import ChatPromptTemplate, MessagesPlaceholder
from langchain.schema import SystemMessage, HumanMessage
# 创建一个PromptTemplate示例
template = "你是一个{职业},请回答以下问题:{问题}"
prompt_template = PromptTemplate(template=template, input_variables=["职业", "问题"])
# 打印生成的提示
filled_prompt = prompt_template.invoke({"职业": "码农", "问题": "什么是人工智能?"})
print("PromptTemplate示例:")
print(filled_prompt)
# 创建一个ChatPromptTemplate示例
system_message = SystemMessage(content="你是一个智能助手,请回答用户的问题。")
messages_placeholder = MessagesPlaceholder(variable_name="messages")
chat_template = ChatPromptTemplate.from_messages([system_message, messages_placeholder, ('system','你猜我是什么人?')])
# 模拟一些对话消息
messages = [
HumanMessage(content="你好,我是CYX。"),
SystemMessage(content="你好,CYX!有什么可以帮助你的吗?"),
HumanMessage(content="什么是人工智能?")
]
# 打印生成的聊天提示
filled_chat_prompt = chat_template.format_prompt(messages=messages)
print("\nChatPromptTemplate示例:")
for message in filled_chat_prompt.to_messages():
print(f"{message.type}: {message.content}")
执行结果:
text='你是一个码农,请回答以下问题:什么是人工智能?'
ChatPromptTemplate示例:
system: 你是一个智能助手,请回答用户的问题。
human: 你好,我是CYX。
system: 你好,CYX!有什么可以帮助你的吗?
human: 什么是人工智能?
system: 你猜我是什么人?
更多详细信息可以查看官方提示词模板导航。
扩展:一种实现更好性能的常见提示技巧是将示例作为提示的一部分。有时这些示例会被硬编码到提示中,但对于更高级的情形,动态选择这些示例可能更好。示例选择器是负责选择示例并将其格式化为提示的类,详情可以查看官方文档。
三、数据连接封装
在 LangChain 中,数据连接封装是其核心功能之一,它允许开发者轻松地将不同来源的数据与大型语言模型(LLMs)集成,以实现更强大和个性化的应用。
3.1、文档加载器(Document Loaders)
LangChain 支持多种类型的数据源,常见的包括:
- 文本文件:如 TXT、PDF、DOCX 等格式的文件,可用于存储文章、报告等文本信息。
- 数据库:像 SQLite、MySQL、PostgreSQL 等关系型数据库,以及 MongoDB 等非关系型数据库。
- 网页:通过网络爬虫获取网页上的文本内容。
- 云存储:例如 AWS S3、Google Cloud Storage 等,用于存储和管理大量数据。
更多的数据源加载器可以查看文档加载器的官方介绍。
文档加载器都实现了 BaseLoader 接口。每个文档加载器都有其特定的参数,但它们都可以通过 .load 方法或 .lazy_load方法调用。以下是一个简单的示例:
loader = WebBaseLoader("http://www.baidu.com")
print(loader.load())
3.2、文本分割器(TextSplitter)
当加载的文档较大时,需要将其分割成较小的文本块(chunk),以便后续处理。LangChain 提供了多种文本分割器,如CharacterTextSplitter、RecursiveCharacterTextSplitter等。
文档拆分有多种策略,每种策略都有其自身的优势:
- 基于长度拆分:基于长度的分割有两种类型,基于Token的分割(TokenTextSplitter)和基于字符的分割(CharacterTextSplitter)。
- 基于文本结构拆分:基于段落、句子和单词,利用这种固有结构的拆分策略,使得既能保持自然语言流畅性、维持语义连贯性,又能适应不同文本粒度级别的拆分,实现类:RecursiveCharacterTextSplitter 。
- 基于文档结构化拆分:对于具有内在结构的文档,例如HTML、Markdown或JSON文件。在这些情况下,根据其结构对文档进行拆分是有益的。
- 基于语义拆分:根据文本的内容进行语义上的分割。例如:利用预训练的自然语言处理模型,如 BERT、GPT 等,对文本进行语义理解和分析。模型可以学习到文本中的语义信息和上下文关系,通过预测文本中的语义边界或关键语义节点,将文本分割成具有完整语义的片段。
具体可以查看官方手册,在此仅以长度拆分为示例:
# 示例文本
text = "这是一个示例文本,用于展示LangChain的中文本分割器。"
# 基于Token分割
token_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
token_splits = token_splitter.split_text(text)
print("基于Token分割结果:")
for split in token_splits:
print(split)
# 基于字符分割
char_splitter = CharacterTextSplitter(
separator="。",
keep_separator=True,
chunk_size=20,
chunk_overlap=5,
is_separator_regex=False
)
char_splits = char_splitter.split_text(text)
print("\n基于字符分割结果:")
for i, split in enumerate(char_splits):
print(f"段落 {i+1}: {split} (长度: {len(split)})")
四、对话历史管理
未完成,待续。。。。。。
五、Chain和Lang Chain Expression Language(LCEL)
六、Agent
七、LangServe
全部评论