cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
AI大模型系列:(十一)经典Transformer架构介绍
Transformer 是一种深度学习模型架构,主要用于处理序列数据,尤其在自然语言处理(NLP)领域表现突出。它由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出,核心在于自注意力机制(Self-Attention),能够捕捉序列中不同位置元素之间的关系。
虽然Transformer架构经过这些年的发展做过很多改进,如:目前很多大模型都采用仅解码器的单向Transformer结构,自回归生成文本。但学习Transformer的原始的架构依然有非常高的价值,能从中理解其核心思想,下图就是从《Attention is All You Need》中拿到的Transformer架构图:
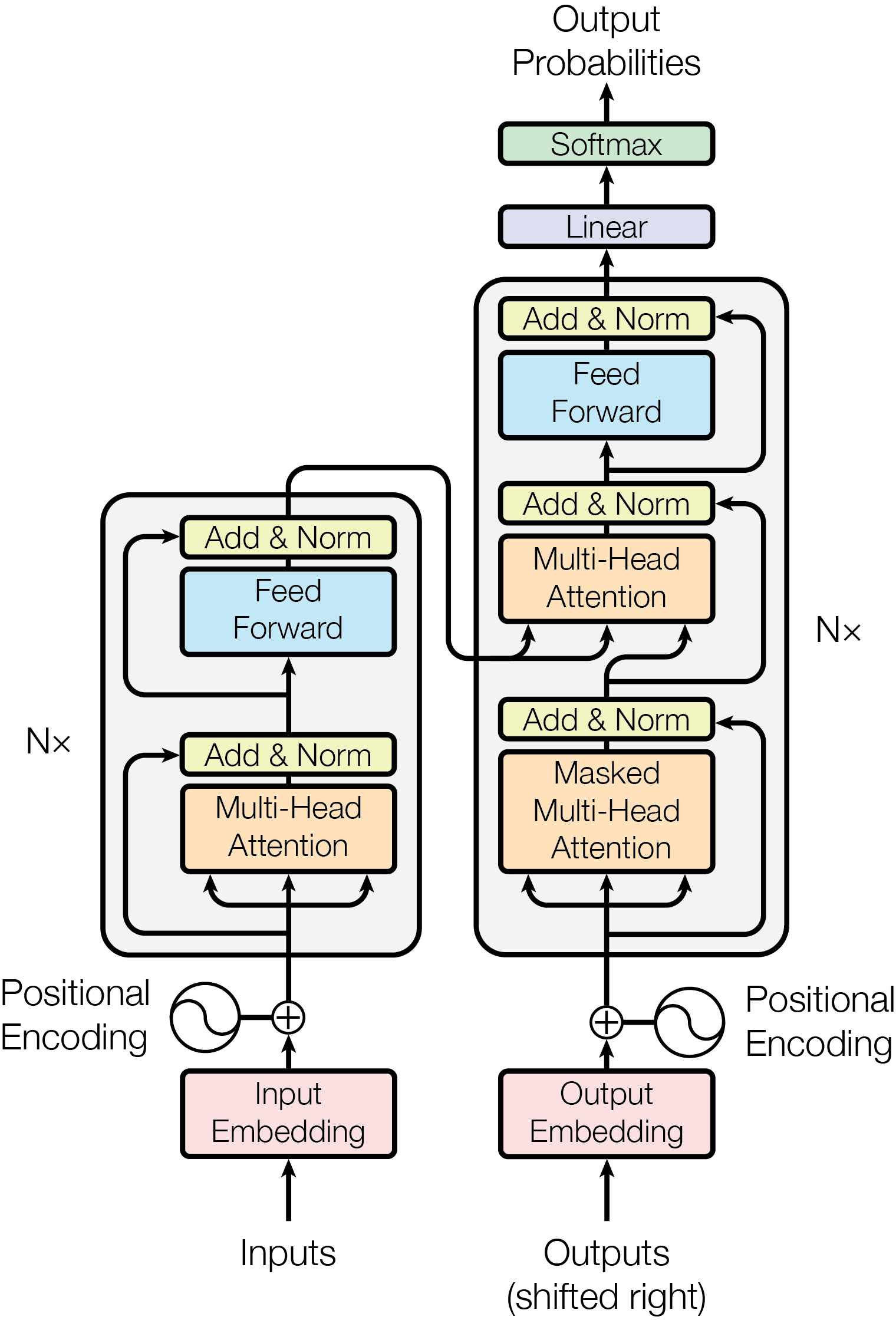
一、功能模块介绍
先对上图内容做个简单的介绍:
左半部分: 编码器(堆叠N个相同层),每层主要包含:
- 多头自注意力(Multi-Head Self-Attention):捕捉输入序列中不同位置之间的依赖关系(做信息的聚合,长距离依赖)。
- 前馈网络(Feed Forward):对注意力输出进行非线性变换。
右半部分: 解码器(堆叠N个相同层),每层主要包含:
- 掩码多头自注意力(Masked Multi-Head Self-Attention):在标准的多头自注意力机制基础上,通过加入掩码(Mask)来屏蔽未来位置的信息,确保模型在生成当前词时只能关注到已生成的过去词,从而满足自回归(Auto-regressive)生成任务的需求。
- 多头自注意力(Multi-Head Self-Attention):捕捉输入序列中不同位置之间的依赖关系(长距离依赖)。
- 前馈网络(Feed Forward):对注意力输出进行非线性变换。
编、解码器之外Embedding和Positional Encoding就是输入部分,Linear和Softmax就是输出部分。
其他细节部分介绍:
- 位置编码(Positional Encoding):为序列中的每个位置生成唯一的编码,弥补自注意力机制对位置不敏感的缺陷。
- 残差连接(Add):将模块的输入与输出相加(如:输出 = 输入 + 子层输出),缓解梯度消失。
- 规范化层(Layer Normalization):对输出进行归一化,加速训练。
- 线性层(Linear):将解码器输出映射到目标语言词表大小的维度。
- Softmax:负责对注意力分数进行归一化,转换生成每个词的概率。
- 掩码(Masking):在解码器的自注意力中屏蔽未来位置的信息。
- 词嵌入(Embedding):把token变成向量(在2017年的经典Transformer中这个向量的维度是512维,到GPT3已经是12288维)。
二、输入层
输入层包括文本嵌入层(Input Embedding+Output Embedding)和Positional Encoding。
2.1、分词(Tokenization)
Tokenization不在Transformer架构中,在此简单的做个了解,详细可以看另一篇文章:《AI大模型系列:(十二)分词(Tokenization)》
大模型处理文本的时候首先会用分词算法把字词拆分为(token),以token为最小的单元在大模型中进行处理。
我们以BET算法为例,进行分词:
每个token从词表中都能找到一个对应的唯一整数ID,这个ID就类似于我们的身份证号。
Transformer架构传入的Inputs就是文本分词后的ID序列,用于后续的Embedding。
2.2、词嵌入(Embedding)
Embedding是为了把输入的数字序列转变为向量表示,希望通过处理这样的高纬空间来捕捉词汇间的关系。
PyTorch库中已经集成了Transformer,我们通过一个示例代码来查看Embedding转换的嵌入向量是怎么样的:
import torch
import torch.nn as nn
# 创建一个嵌入层对象,输入词汇量为10,每个词的嵌入维度为3
embedding = nn.Embedding(10, 3)
# 定义一个输入张量,填入一些示例数据:包含两个序列,每个序列有5个词汇索引
input = torch.LongTensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 0]])
# 使用嵌入层将输入的词汇索引转换为对应的嵌入向量,并打印输出
print(embedding(input))
执行结果如下所示,两个序列[1, 2, 3, 4, 5], [6, 7, 8, 9, 0]被转换为维度为3的向量。
[-0.4225, -0.4956, 0.2876],
[-0.3806, 1.6526, -0.1450],
[-0.5518, 1.9686, 0.3392],
[ 0.6158, -0.5368, -0.3489]],
[[-1.1142, -1.7878, 1.1351],
[ 0.2152, -0.4151, 1.5877],
[ 1.4548, -2.3441, -1.0871],
[ 1.2150, -2.3820, 0.4889],
[-0.7432, 0.4534, 0.1362]]], grad_fn=<EmbeddingBackward0>)
2.3、位置编码(Positional Encoding)
在Transformer编码器结构中并没有对词汇位置信息的处理模块,需要在Embedding层后加入位置编码器,将词汇位置信息加入到词嵌入的张量中。(一个字在不同的位置肯定会产生不同的语义,所以传入位置编码是必要的。)
功能:为序列中的每个位置生成唯一的编码,弥补自注意力机制对位置不敏感的缺陷。
涉及公式:
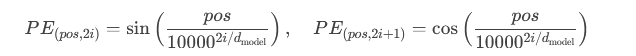
实现:与词嵌入相加后输入模型。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
位置编码器类的初始函数,共有三个参数,分别是d_model、dropout和max_len。
d_model:嵌入向量的维度
dropout:随机失活概率,置0的比率(让神经网络中的神经元失效的比率,其作用是防止过拟合)
max_len:位置编码矩阵的最大长度
"""
super(PositionalEncoding, self).__init__()
# 实例化Dropout层,并将dropout传入
self.dropout = nn.Dropout(p=dropout)
# 初始化位置编码矩阵,它是一个0阵,矩阵大小是max_len行,d_model列
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵,在此词汇的绝对位置就以它的索引表示
# arange()函数创建一个从0到max_len-1的序列(一维向量)
# unsqueeze()函数的作用是增加维度,这里增加一维,因为后面要进行矩阵运算,所以需要增加一维
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 定义一个变换矩阵,跳跃式的初始化
# torch.arange(0, d_model, 2)生成一个从 0 到 d_model-1 步长为 2的序列。
# -(math.log(10000.0) / d_model) 算了一个常数,用于缩放张量的指数部分
# torch.arange生成的序列的每个元素乘以这个常数
# torch.exp() 再计算出每个元素的指数值
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 将前面定义的变化矩阵进行奇数偶数的分别赋值
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 将位置编码矩阵pe进行维度变换,将其从二维矩阵变为三维矩阵
pe = pe.unsqueeze(0)
# 将位置编码矩阵注册成模型的buffer, 这个buffer不是模型中的参数,不跟随优化器同步更新
# 注册成buffer后,我们就可以在模型保存后重新加载的时候,将这个位置编码器和模型参数一起加载进来。
self.register_buffer('pe', pe)
def forward(self, x):
# 修改维度匹配方式
# x形状: [batch_size, seq_len, d_model]
# pe形状: [1, max_len, d_model]
x = x + self.pe[:, :x.size(1), :] # 截取与输入序列长度匹配的位置编码
return self.dropout(x)
三、编码器(Encoder)
结构:
由 N个相同的编码器层堆叠而成(原论文中N=6,GPT3已经到了96层,GPT4、Lama3.1就是120层)。
每个编码器层有2个子层
输入:词嵌入向量(Word Embeddings) + 位置编码(Positional Encoding)。
3.1、 多头自注意力(Multi-Head Self-Attention)
功能:捕捉输入序列中不同位置之间的依赖关系(长距离依赖)。
机制:
- 将输入拆分为多个“头”(Head),每个头独立学习不同的注意力模式。
- 通过计算 Query、Key、Value 矩阵的相似度,生成注意力权重。
公式:
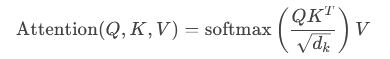
输出:多个头的注意力结果拼接后通过线性变换。
3.1.1、注意力机制
注意力机制中有3个向量: Q(Query,查询向量)、K(Key,键向量)、V(Value,值向量),可以用一个形象的比喻来说明注意力机制。
Query(Q):就像你脑海中对要找书籍的描述,比如 “我想找一本关于历史故事的书”,这个描述就是 Query,它代表着你的需求和目标。
Key(K):图书馆里每本书的标签、简介,这些信息就像是 Key。它们是书籍内容的一种概括性标识,用来和你的需求(Query)进行匹配。
Value(V):而每本书的具体内容则是 Value。一旦通过书籍标签(Key)和你的需求(Query)匹配上了,你就能获取到对应的书籍内容(Value)。
当你走进图书馆,脑海里带着对书籍的需求(Query)。你开始扫视每本书的标签和简介(Key),通过比对这些 Key 和你的 Query,找到和你需求最匹配的书。一旦找到匹配的书,你就可以翻开它,阅读里面具体的内容(Value),获取到你想要的知识。注意力机制也是如此,通过 Query 在大量的 Key 中寻找匹配,从而定位到对应的 Value,帮助模型更有针对性地处理信息 。
如果Q、K、V相同就是自注意力机制。它是通过文本自身来表达自己,从中提取关键词表述它,相当于对文本自身的一次特征提取。
注意力机制在《Attention is All You Need》中也给出了实现的结构图,如下:
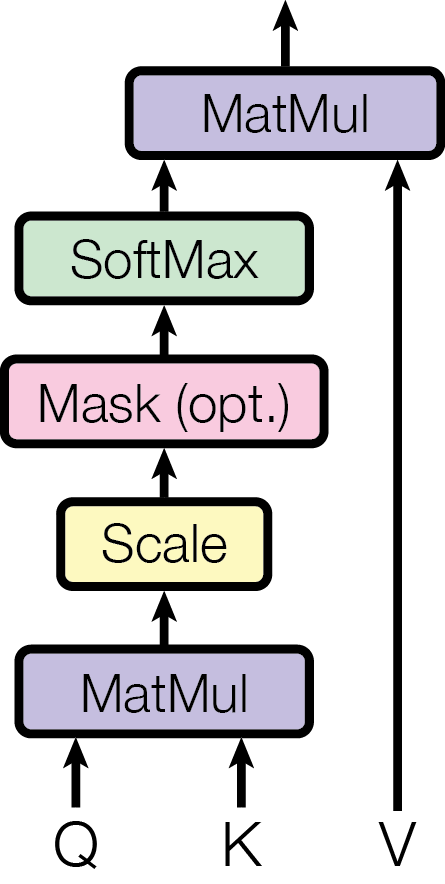
- 输入:图中的 Q(Query,查询向量)、K(Key,键向量)和 V(Value,值向量)是输入。它们通常是通过对输入数据进行线性变换得到的,在自然语言处理等任务中,它们分别用于寻找相关信息、标识信息以及提供实际信息。
- 矩阵乘法(MatMul):首先,Q和K进行矩阵乘法运算,这一步的目的是计算每个查询向量Q与所有键向量K之间的相似度。
- 缩放(Scale):将上一步矩阵乘法的结果进行缩放,通常是除以 , 是 的维度。缩放的目的是为了防止在计算相似度时,数值过大导致 SoftMax 函数的梯度消失问题。
- 掩码(Mask (opt.)):这是一个可选步骤。在某些场景下,如处理序列数据时,需要屏蔽掉一些无效的位置(例如填充的部分),掩码操作可以将这些位置的分数设为一个非常小的值(如负无穷),使其在 SoftMax 计算中对结果的影响可以忽略不计。
- SoftMax 函数:对经过掩码(如果有)和缩放后的结果应用 SoftMax 函数,将其转换为概率分布,表示每个键值对与查询向量的相关程度。
- 矩阵乘法(MatMul):最后,将 SoftMax 输出的概率分布与 进行矩阵乘法,得到注意力机制的最终输出,这个输出综合了所有值向量的信息,并且根据查询向量与键向量的相似度进行了加权。
通过这样的流程,注意力机制能够有效地捕捉输入数据中不同部分之间的依赖关系 。
代码示例:
"""
query, key, value: 代表注意力的三个输入张量
mask: 代表注意力掩码张量
dropout: 传入的dropout实例化对象,用于防止过拟合
"""
# 首先将query的最后一个维度提取出来,代表的是词嵌入的维度
d_k = query.size(-1)
# 按照注意力计算公式,将query和key的转置进行矩阵乘法,然后除以缩放系数,得到注意力分数
# 这里的缩放系数,是d_k的倒数,是为了防止注意力分数过大,导致softmax函数的梯度消失,从而影响训练效果
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 判断是否使用掩码张量,如果使用,则将注意力分数进行遮罩,并使用填充值-1e9来替换
# 这样,在softmax函数中,这些值会被忽略,从而实现注意力掩码的作用
if mask is not None:
# 将注意力分数进行遮罩,并使用填充值-1e9来替换
scores = scores.masked_fill(mask == 0, -1e9)
# 对scores的最后一个维度上进行softmax操作,得到注意力权重
# 这里的dim=-1,代表对最后一个维度进行softmax操作
p_attn = F.softmax(scores, dim=-1)
#判断是否使用dropout
if dropout is not None:
# 如果使用,则对注意力权重进行dropout操作
p_attn = dropout(p_attn)
# 最后,将注意力权重和value进行矩阵乘法,得到最终的注意力输出
return torch.matmul(p_attn, value), p_attn
3.1.2、多头自注意力机制详解
多头自注意力机制(Multi - Head Self - Attention)是自注意力机制的扩展。它包含多个 “头”,每个头独立执行自注意力计算,相当于多个不同的子空间同时进行自注意力运算。例如,有 8 个头,就相当于有 8 个独立的自注意力机制并行工作。每个头关注输入序列的不同方面信息,捕捉不同角度的语义关联。之后将这些头的输出拼接起来,并通过一个线性变换进行融合,得到最终的输出。
假设一个token经过Embedding+Positional Encoding得到一个512维的向量,这512维的向量就会分给各个“头”进行计算,计算后再合并输出。
多头注意力机制在《Attention is All You Need》中也给出了结构图,如下:
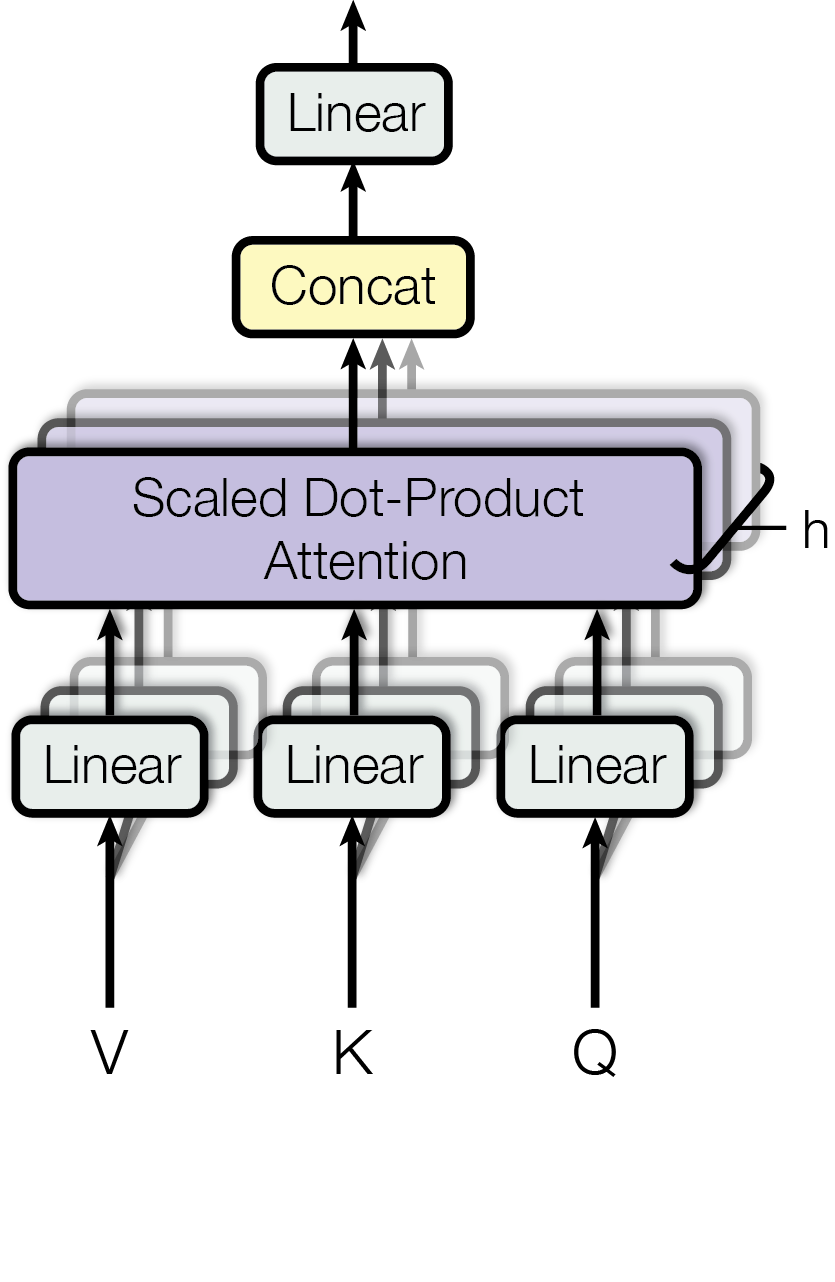
- 输入模块(Q、K、V):Q(Query,查询向量)、K(Key,键向量)和 V(Value,值向量)是初始输入。在实际应用中,它们通常是通过对原始输入进行线性变换得到,用于后续的注意力计算。
- 线性变换模块(Linear):图中有多个 “Linear” 模块。底部的三个 “Linear” 分别对输入的 Q、K、 V进行线性变换。这一步是为了将输入投影到不同的子空间,得到多个不同的 Q、K、V 版本,以适配不同 “头” 的计算。顶部的 “Linear” 模块则是在多头计算结果拼接后,对拼接后的向量进行一次线性变换,将其映射到合适的维度,得到最终的输出。
- 缩放点积注意力模块(Scaled Dot - Product Attention):这是核心计算模块,缩写为 “h” 的多个并行模块代表多头。每个 “h” 独立执行缩放点积注意力计算,其内部计算流程和3.1.1中的注意力机制流程一致,即先计算Q与K的相似度,经过缩放、掩码(可选)、SoftMax 等操作后与V相乘,从而得到每个头的注意力输出。
- 拼接模块(Concat):“Concat” 模块负责将多个头(即多个 “Scaled Dot - Product Attention” 模块)的输出结果按照一定顺序拼接起来,将不同子空间捕捉到的信息整合在一起,为后续的线性变换提供综合的输入。
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,从而提示模型效果。
代码逻辑:
# 所以需要用clone函数将他们一同初始化到一个网络层列表对象中
def clone(module, N):
"""
module: 线性层
N: 线性层的个数
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# 实现多头注意力机制
class MultiHeadAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
"""
head: 多头注意力机制的头数
embedding_dim: 词嵌入的维度
dropout: 随机失活概率
"""
super(MultiHeadAttention, self).__init__()
# 要确认:多头的数量head需要整除词嵌入的维度embedding_dim
assert embedding_dim % head == 0
# 得到每个头获得的词向量维度
self.d_k = embedding_dim // head
self.head = head
self.embedding_dim = embedding_dim
# 获得线性层,要获得4个,分别是QKV以及最终输出线性层
self.linears = clone(nn.Linear(embedding_dim, embedding_dim), 4)
# 初始化注意力张量
self.attention = None
# 初始化随机失活层
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
query,key,value: 代表注意力的三个输入张量
mask: 代表注意力掩码张量
"""
# 判断是否使用掩码张量
if mask is not None:
# 如果使用,则将注意力掩码张量进维度扩充
mask = mask.unsqueeze(1)
# 获得batch_size
batch_size = query.size(0)
# 首先使用zip将网络层和输入连接到一起,模型的输出利用view和transpose进行维度和形状的改变
query, key, value = \
[model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))]
# 计算注意力张量
x, self.attention = attention(query, key, value, mask=mask, dropout=self.dropout)
# 得到每个痛殴的计算结果是4维张量,需要进行形状的转换
# 前面已经将1,2两个维度进行过转置,在这里要重新转置回来
# 注意:经历transponse方法后,必须要使用contiguous方法,不然无法使用view方法
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)
# 最后将x输入线性层列表中的最后一个线性层中,得到最终的输出
return self.linears[-1](x)
3.2、前馈网络(Feed Forward Network, FFN)
前馈网络:就是具有两层线性层的全连接网络,其作用就是通过增加两层网络来增强模型的能力。
功能:对注意力输出进行非线性变换。
结构:两层全连接线性层,中间使用ReLU激活函数。
ReLU公式:当输入 x>0 时,输出为 x;否则输出为 0。
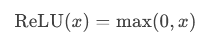
前馈网络公式:
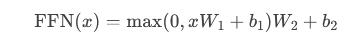
W1,W2 是权重矩阵,b1,b2 是偏置项。ReLU作用于第一个线性变换的输出(即 xW1+b1),将负值置零后,再进行第二个线性变换。
代码示例:
def __init__(self, d_model, d_ff, dropout = 0.1):
"""
d_model: 词嵌入的维度,同时也是两个线性层的输入维度和输出维度
d_ff: 第一个线性层的输出维度,和第二个线性层的输入维度
dropout: 随机失活概率
"""
super(FeedForwardNetwork, self).__init__()
# 定义两层全连接线性层
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
"""
x: 代表上一层的输出
首先将x输入到第一个线性层中,然后使用ReLU激活函数,再经历dropout进行随机失活
最后将输出输入到第二个线性层中
"""
return self.w_2(self.dropout(F.relu(self.w_1(x))))
3.3、规范化层
Transformer模型中的规范化层位于每个子层(如自注意力或前馈网络)的输出与残差连接相加之后。
其核心作用是稳定训练过程、加速收敛,并缓解梯度消失问题。
随着网络层数增加,通过多层计算后参数可能开始出现过大或过小的情况,这样可能导致机器学习过程出现异常,模型可能收敛非常慢,因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内。
公式:
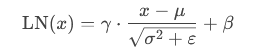
其中,μ 和 σ2 为当前样本特征的均值和方差,ε 为小常数防止除零。使用均值和对方差进行归一化,再通过可学习的参数 γ(缩放)和 β(偏移)调整。
代码示例:
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""
features: 词嵌入的维度
eps: 一个很小的数,用于防止分母为0
"""
super(LayerNorm, self).__init__()
# 定义两个可训练的参数,用于计算归一化后的结果,将其用nn.Parameter()包装起来,代表他们也是模型中的参数
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# x:代表上一层网络的输出
# 首先对x进行最后一个维度的求均值操作,同时保持输出维度和输入维度一致
mean = x.mean(-1, keepdim=True)
# 对x进行最后一个维度的求方差操作,同时保持输出维度和输入维度一致
std = x.std(-1, keepdim=True)
# 按照规范化公式进行计算并返回
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
3.4、子层连接结构
Transformer架构中的子层连接结构是残差连接和规范化层的结合。即下图红线部分:
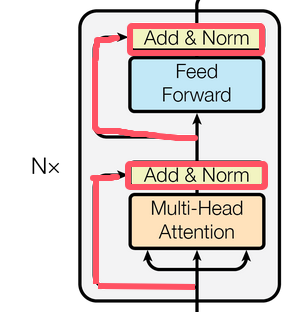
残差连接:将子层的输入直接与其输出相加。
公式表达:
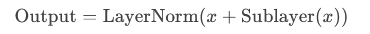
x表示子层的输入,Sublayer(x)表示子层的计算结果。
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
"""
size: 输入向量的维度
dropout: 置零比率
"""
super(SublayerConnection, self).__init__()
# 实例化一个规范化层的对象
self.norm = LayerNorm(size)
# 实例化一个dropout层对象
self.dropout = nn.Dropout(dropout)
self.size = size
def forward(self, x, sublayer):
# x: 代表上一层传入的张量
# sublayer: 代表上一层传入的函数,该函数的输入是x,输出是注意力分数
# 将x进行规范化,并传入sublayer函数,得到新的x,再进入dropout层,最后+x进行残差连接
return x + self.dropout(sublayer(self.norm(x)))
3.5、编码器层实现逻辑
编码器层作为编码器的组成单元,每个编码器层完成一次对输入的特征提取。N个相同的层堆叠在一起就是编码器。
上文已经把编码器层中的所有组件都实现了一遍,在此通过代码把实现下图功能。
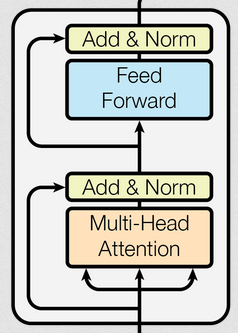
代码示例:
def __init__(self, size, self_attn, feed_forward, dropout):
"""
:param size: 输入向量维度
:param self_attn: 自注意力模块
:param feed_forward: 前馈神经网络模块
:param dropout: dropout比率
"""
super(EncoderLayer, self).__init__()
# 将两个实例化对象和参数传入类种
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
# 编码器中有2个子层连接结构,使用clones函数进行操作
self.sublayer = clone(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
# x 为上一层传入张量
# mask 代表掩码张量
# 首先让x经过第一个子层连接结构,内部包含多头自注意力机制
# 再让张量经过第二个子层连接结构,其中包含前馈连接网络
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
3.6、编码器实现逻辑
编码器即是多个编码器层堆叠,如下所示:
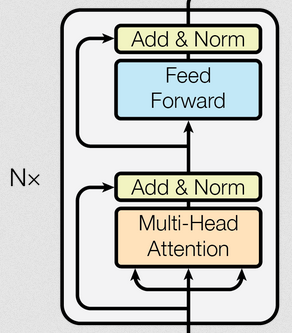
代码示例:
class Encoder(nn.Module):
def __init__(self, layer, N):
# layer: 编码器层
# N: 编码器层的数量
super(Encoder, self).__init__()
# 构建N个编码器层
self.layers = clones(layer, N)
# 初始化一个规范化层,作用在编码器的最后面
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# x: 代表上一层输出的张量
# mask: 代表注意力掩码张量
# 让x依次经历N个编码器层的处理,左后再经过规范化层就可以输出了
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
def clones(module, N):
# N:克隆的个数
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
四、解码器(Decoder)
结构:同样由 N个相同层 堆叠(N=6)。
输入:前一步生成的输出(训练时使用目标序列的嵌入向量 + 位置编码)。
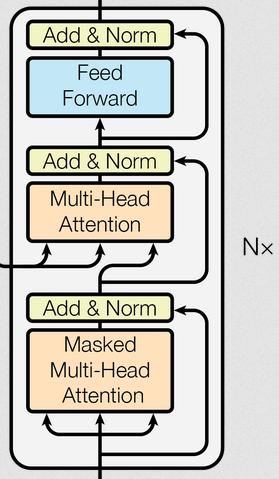
解码器中多头注意力机制、规范化层、前馈网络、子层连接结构都是与编码器的实现相同,这里就不再重复,可以直接拿来构件解码器层。
与编码器的不同点:
- 多了一个Masked Multi-Head Attention,这只是在多头注意力机制中加入了掩码,用于在生成序列时避免模型“看到”未来的信息(如生成第t个词时,只能依赖前t−1个词)。
- Multi-Head Attention中是以编码器的输出作为 Key 和 Value,解码器Masked Multi-Head Attention的结果残差 & 规范化后作为Query。
4.1、掩码张量
用来遮掩张量中的数值,把数值替换为0或1(可以自己决定是0还是1)达到遮掩的目的。
在Transformer中,掩码张量的主要作用是在attention机制中,因为模型训练时会把整个输出结果都一次性Embedding,所以在生成attention张量中的值计算可能会已知未来信息,解码器的输出是多层解码器循环生成的,因此为了防止未来信息被提前利用,就需要进行遮掩。
代码示例:
import numpy as np
import torch
# 构件掩码张量函数
def subsequent_mask(size):
" size: 代表掩码张量的大小,形成一个方阵(实际处理数据时是按批次处理的,所以需要构建一个方阵,下面的1就可以用批次的大小代替)"
attn_shape = (1, size, size)
# 使用np.oens()先构件一个全1的张量,然后利用np.triu()行程上三角矩阵
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# 使得这个三角矩阵反转
return torch.from_numpy(1 - subsequent_mask)
size = 5
sm = subsequent_mask(size)
plt.figure(figsize=(5, 5))
mask = subsequent_mask(20)
print(mask)
plt.imshow(mask[0])
plt.show()
结果显示:
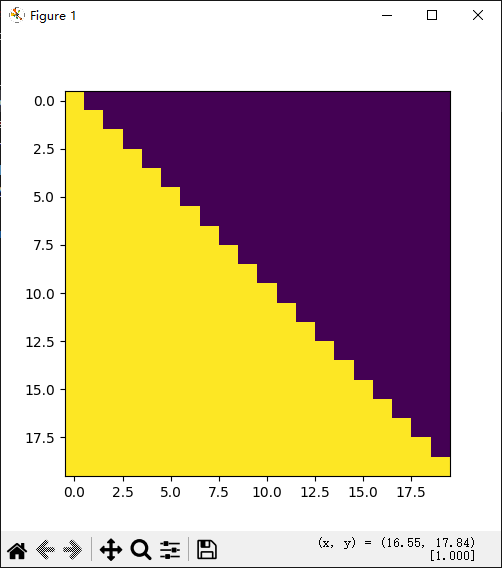
- 可视化方阵黄色的是1的部分,表示被遮掩,紫色代表没有被遮掩的信息。
- 横坐标可以代表目标词汇的位置,纵坐标代表可查看的位置。
- Transformer在循环编解码时,会根据当前位置,来决定哪些位置的词可以查看,哪些位置的词不可以查看。
- 比如横坐标0时纵坐标都是黄色,表示都被遮掩。往右一格即表示已编解码了第一个token,则有一个紫色可以被查看到,随着编解码越多越往右能看到的数据越多。
4.2、 解码器层
作为解码器的组成单元,每个解码器层根据给定的输入进行特征提取。每个解码器层都要经过三个子层的计算。
代码示例:
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
"""
:param size: 词嵌入维度
:param self_attn: 自注意力模块
:param src_attn: 源注意力模块
:param feed_forward: 前馈神经网络模块
:param dropout: 丢弃概率
"""
super(DecoderLayer, self).__init__()
# 初始化各个模块
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.size = size
# 按照解码器层的结构图,使用clones函数克隆3个子层连接对象
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
"""
:param x: 上一层传入的张量
:param memory: 编码器输出的张量
:param source_mask: 源序列的mask张量
:param target_mask: 目标序列的mask张量
"""
# 构建解码器层结构图
m = memory
# 第一步,第一个子层,掩码多头自注意力机制的子层
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 第二步,第二个子层,Q!=K=V的多头注意力机制的子层
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 第三步,第三个子层,前馈神经网络的子层
return self.sublayer[2](x, self.feed_forward)
4.3、 解码器实现逻辑
根据编码器的结果以及上一次预测的结果,对下一次可能出现的值进行特征表示。
代码示例:
class Decoder(nn.Module):
def __init__(self, layer, N):
"""
layer: 解码器层的对象
N: 解码器的层数
"""
super(Decoder, self).__init__()
# 利用clons函数克隆N个layer
self.layers = clones(layer, N)
# 实例化一个规范化层
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
# x: 代表目标数据的嵌入表示
# memory :代表编码器的输出张量
# source_mask: 代表源数据的掩码张量
# target_mask: 代表目标数据的掩码张量
# 要将x依次经历所有的编码器层处理,最后通过规范层
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
五、输出部分
输出部分包括线性层和softmax层,如下图所示:
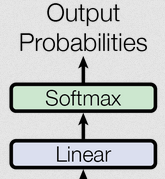
Transformer通过线性层和Softmax 层将模型的隐藏状态转换为最终的输出概率分布。
- 线性层,也叫全连接层,在 Transformer 的输出部分,其主要作用是将 Transformer 编码器或解码器输出的特征向量映射到目标空间,为后续的 Softmax 层做准备。它通过矩阵乘法和加法操作,对输入的特征进行线性变换,以调整特征的维度和表示方式,使模型能够更好地捕捉数据中的复杂关系。
- Softmax 层通常用于将线性层输出的得分转换为概率分布,使得模型的输出可以被解释为各个类别或选项的概率。在 Transformer 中,它主要用于生成文本等任务中,计算每个可能输出单词或符号的概率,从而指导模型生成最可能的结果。
代码示例:
def __init__(self, d_model, vocab_size):
# d_model: 词嵌入维度
# vocab: 词表大小
super(Generator, self).__init__()
# 定义一个线性层,作用是完成网络输出维度的变换
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
# x代表上一层的输出张量
# 首先将x送入线性层中,让其经历softmax处理
return F.log_softmax(self.proj(x), dim=-1)
六、参考文档
《Attention is All You Need》:https://arxiv.org/html/1706.03762v7
《图解GPT - 2(可视化Transformer语言模型)》:https://jalammar.github.io/illustrated-gpt2/
《图解Transformer》:https://jalammar.github.io/illustrated-transformer/
全部评论