cyxCoder
明天你会感谢今天奋力拼搏的你。
ヾ(o◕∀◕)ノヾ
Redis系列:(二)Redis的高级特性和应用
一、Redis的慢查询
慢查询的阈值默认为10毫秒(注意:这个时间是执行指令的时间,不包括网络传输时间和Redis线程排队时间)
相关配置介绍
- 慢查询阈值设置的字段为:
slowlog-log-slower-than 10000表示慢查询阈值为10毫秒,单位为微妙,如果设置为小于0的数则表示不记录慢查询。 - Redis的慢查询存储在内存中,在一个showlog的链表中
slowlog-max-len 128表示保存的慢查询队列的长度。
如下图所示为Redis配置文件中对慢查询的默认设置,

相关命令示例:
# 设置慢查询阈值为0(这里是为了方便测试,生产环境不要这样)
config set slowlog-log-slower-than 0
# 上面的命令服务器重启后会失效,想要永久生效,可以用如下命令把改动的参数回写到redis的配置文件中
config rewrite
# 获取慢查询日志的相关配置
CONFIG GET slowlog-*
# 获取慢查询日志记录,语法:SLOWLOG GET [数量],数量表示显示日志条数
SLOWLOG GET 2
# 获取当前慢查询日志的数量
SLOWLOG LEN
# 清空慢查询日志
SLOWLOG RESET生产配置优化建议
- slowlog-log-slower-than建议设置为 1~10 毫秒( 1000~10000)
- 增大日志容量,生产环境slowlog-max-len可设置 1000~10000
注意:
- 关于慢查询的日志分析,Redis没有提供分析的指令,需要通过SLOWLOG命令把日志拿出来自己分析。
- 生产也可以使用定时任务把日志结果存到持久化层中,以便后续进行分析。
二、Pipeline
Redis Pipeline(管道)是一种批量执行命令的优化技术,用于减少客户端与服务器之间的网络往返延迟(RTT),显著提升高并发场景下的吞吐量。客户端将多个命令打包一次性发送给服务器,服务器处理完所有命令后,一次性返回所有结果。
使用Pipeline的注意事项:
- Pipeline 中的命令会顺序执行,若包含耗时操作(如KEYS *、SORT),会阻塞后续命令的处理。
- 对于大批量数据,还是要采取分批处理的方式,防止Redis内存激增。一般限制500条以下数据。
Java代码示例:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
import java.util.List;
public class RedisPipelineExample {
public static void main(String[] args) {
// 连接 Redis 服务器
try (Jedis jedis = new Jedis("localhost", 6379)) {
// 示例 1:批量写入
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
pipeline.set("key" + i, "value" + i);
}
// 执行批量操作
List<Object> results = pipeline.syncAndReturnAll();
System.out.println("批量写入完成,共执行 " + results.size() + " 条命令");
// 示例 2:批量读取(使用 Response 对象获取结果)
Pipeline getPipeline = jedis.pipelined();
Response<String> key1 = getPipeline.get("key1");
Response<String> key2 = getPipeline.get("key2");
Response<Long> incrResult = getPipeline.incr("counter");
// 执行并获取结果
getPipeline.sync();
System.out.println("key1: " + key1.get());
System.out.println("key2: " + key2.get());
System.out.println("counter 自增后的值: " + incrResult.get());
// 示例 3:混合操作(写入后读取)
Pipeline mixedPipeline = jedis.pipelined();
mixedPipeline.set("user:1", "Alice");
mixedPipeline.hset("user:1:info", "age", "30");
mixedPipeline.get("user:1");
mixedPipeline.hgetAll("user:1:info");
List<Object> mixedResults = mixedPipeline.syncAndReturnAll();
System.out.println("混合操作结果:");
for (Object result : mixedResults) {
System.out.println(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}pipeline内置了很多与命令同名的方法,直接调用即可。
获取结果的方式有两种,示例中都有覆盖:
- 使用 syncAndReturnAll() 返回所有命令的执行结果列表
- 或使用 Response<T> 对象获取特定命令的结果(需先声明,后调用 sync())
三、事务
Redis 事务是一组命令的集合,它可以确保多个命令按顺序执行,且在执行过程中不会被其他客户端的请求打断。
相关命令介绍:
- MULTI 命令:开启一个事务块,后续命令将被加入队列中。
- EXEC 命令:执行事务队列中的所有命令。
- DISCARD 命令:取消事务,清空队列中的所有命令。
- WATCH 命令:监控一个或多个键,在事务执行前若键被修改则事务失败(乐观锁)。
与传统关系型数据库的事务相比,Redis的事务非常的鸡肋,只能判断语法层面的错误进行回滚,更适合处理非强一致性要求的场景,不能保证事务的原子性和一致性。
如下图所示,命令格式正确但执行时出错,错误命令执行错误,但不会影响其它命令的正常执行:
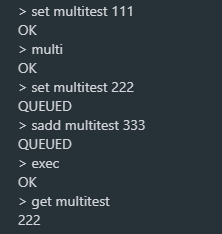
注意:PipeLine是客户端封装所有命令组一起批量执行,能提升吞吐量。而事务依然是普通命令,每个命令都会进行网络传输,只是在MULTI和EXEC中间的命令Redis先放到缓冲区中,EXEC提交时才真正执行。
四、Lua
LUA脚本语言是C开发的,类似存储过程,具体的Lua语法可以查看:《Lua教程 | 菜鸟教程》。
使用LUA脚本的好处:
- 减少网络开销,在Luau脚本中可以把多个命令放在同一个脚本中运行。
- 原子操作,Redis会将整个脚本作为一个整体执行,中间不会被其它命令插入。(因为Redis是单线程执行命令)
- 复用性,客户端发送的脚本会存储在Redis中,这意味着其它客户端可以复用这一脚本完成同样的逻辑。
核心命令介绍:
1、执行Lua脚本
- 语法:
EVAL script numkeys key [key ...] arg [arg ...] - 参数:
- script:Lua 脚本内容
- numkeys:键名参数的个数
- key [key ...]:键名参数,在 Lua 中通过 KEYS[1], KEYS[2] 访问
- arg [arg ...]:附加参数,在 Lua 中通过 ARGV[1], ARGV[2] 访问
示例:
EVAL "return {KEYS[1], KEYS[2], ARGV[1], ARGV[2]}" 2 key1 key2 first second2、脚本加载到Redis缓存中
- 语法:
SCRIPT LOAD script - 参数:script:Lua脚本内容
- 返回:SHA1哈希值
示例:
SCRIPT LOAD "return {KEYS[1], KEYS[2], ARGV[1], ARGV[2]}'"
# 返回结果
493d4552555dd9618f79b2b6ef18f8a89fd8f43、执行缓存的脚本
- 语法:
EVALSHA sha1 numkeys key [key ...] arg [arg ...] - 参数:
- sha1:SHA1哈希值(SCRIPT LOAD命令返回的值)
- numkeys:键名参数的个数
- key [key ...]:键名参数,在 Lua 中通过 KEYS[1], KEYS[2] 访问
- arg [arg ...]:附加参数,在 Lua 中通过 ARGV[1], ARGV[2] 访问
示例:
EVALSHA 493d4552555dd9618f79b2b6ef18f8a89fd8f4 2 key1 key2 first second五、发布与订阅
Redis的发布订阅功能比较鸡肋,在此做一下简单的介绍。
概念介绍:
- 发布者(Publisher):向指定频道发送消息的客户端
- 订阅者(Subscriber):监听特定频道获取消息的客户端
- 频道(Channel):消息的逻辑分组,用于区分不同类型的消息(类似于MQ中的Topic)
核心命令介绍:
- 订阅一个或多个频道,语法:
SUBSCRIBE channel [channel …] - 向频道发布消息,语法:
PUBLISH channel message - 取消订阅的频道,如果没指定频道表示取消所有订阅,语法:
UNSUBSCRIBE [channel …]
为什么比较鸡肋?
- 无消息持久化:消息发布后若无人订阅则丢失
- 不保证可靠性:网络问题可能导致消息丢失
- 无队列机制:无法处理消息堆积(需依赖其他组件)
- 单线程处理:高并发场景下可能成为瓶颈
六、Stream
Redis 5.0版本发布的Stream功能,其借鉴了kafka的设计提供了持久化的能力,用于支持消息中间件(可以算是发布订阅功能的替代)。
6.1、概念介绍
- Stream:消息的持久化存储容器,支持多生产者多消费者模型
- 消息(Message):结构化数据,每个消息包含唯一 ID(ID格式:时间戳-序列号) 和键值对(Hash类型)
- 消费者组(Consumer Group):多个消费者组成的组,支持负载均衡消费,多个消费者组可以消费同一个Stream,但它们之间是独立的互不干扰。
- 消费者(Consumer):组内的单个消费者,组内独立维护消费进度
6.2、核心命令介绍
消息队列相关命令:
- 1、XADD:添加消息,语法:
XADD stream-key [MAXLEN count] * field value [field value ...]- stream-key:消息的主题(Topic),用于标识消息流。
- MAXLEN(可选):设置流的最大长度,超出时自动删除旧消息。
- *:自动生成唯一的消息ID(格式:时间戳-序列号)。
- field value:消息的键值对,可重复添加多个字段。
- 2、XTRIM:对流进行修剪,限制长度,语法:
XTRIM stream-key MAXLEN [~] count- stream-key:目标流的名称。
- MAXLEN:必选参数,指定流的最大长度。
- ~(可选):近似修剪模式,允许Redis以更高效但不精确的方式删除消息。
- count:保留的最大消息数量,超出部分将被删除。
- 3、XDEL:删除消息,语法:
XDEL stream-key message-id [message-id ...]- stream-key:目标流的名称。
- message-id:要删除的消息ID,支持批量删除。
- 4、XLEN:获取流的消息数量,语法:
XLEN stream-key- stream-key:目标流的名称。
- 返回值:流中当前的消息总数(包括未删除的消息)。
- 5、XRANGE:获取消息列表(按ID升序),语法:
XRANGE stream-key start end [COUNT count]- stream-key:目标流的名称。
- start/end:消息ID范围(如
0-0表示最小ID,$表示最大ID)。 - COUNT(可选):限制返回的消息数量,用于分页。
- 6、XREVRANGE:反向获取消息列表(按ID降序),语法:
XREVRANGE stream-key end start [COUNT count]- 参数含义:与
XRANGE相同,但返回顺序相反。
- 参数含义:与
- 7、XREAD:阻塞或非阻塞读取消息,语法:
XREAD [BLOCK milliseconds] STREAMS stream-key [stream-key ...] ID [ID ...]- BLOCK(可选):阻塞模式,指定超时时间(毫秒),无新消息时等待。
- STREAMS:必选参数,后跟多个流名称。
- ID:每个流的起始读取位置(如
$表示从最新消息开始)。
消费者组相关命令:
- 1、XGROUP CREATE:创建消费者组,语法:
XGROUP CREATE stream-key group-name id [MKSTREAM]- stream-key:目标流的名称。
- group-name:消费者组的名称。
- id:起始消息ID(
0-0表示从最早消息开始,$表示从最新消息开始)。 - MKSTREAM(可选):若流不存在则自动创建。
- 2、XREADGROUP GROUP:从消费者组读取消息,语法:
XREADGROUP GROUP group-name consumer-name [BLOCK milliseconds] [COUNT count] STREAMS stream-key [stream-key ...] >- GROUP:必选参数,指定组名和消费者名。
- BLOCK/COUNT:同
XREAD,支持阻塞和分页。 - >:表示读取未被任何消费者处理过的新消息。
- 3、XACK:标记消息为“已处理”,语法:
XACK stream-key group-name message-id [message-id ...]- 参数含义:将指定消息标记为已处理,从待处理列表(PEL)中移除。
- 4、XGROUP SETID:重置消费者组的起始位置,语法:
XGROUP SETID stream-key group-name id- id:新的起始消息ID,影响后续
XREADGROUP的读取位置。
- id:新的起始消息ID,影响后续
- 5、XGROUP DELCONSUMER:删除消费者,语法:
XGROUP DELCONSUMER stream-key group-name consumer-name- 参数含义:移除指定消费者,并将其未处理的消息转移到其他消费者。
- 6、XGROUP DESTROY:删除消费者组,语法:
XGROUP DESTROY stream-key group-name- 参数含义:彻底删除消费者组及其状态信息。
- 7、XPENDING:查看待处理消息,语法:
XPENDING stream-key group-name [start end count [consumer-name]]- 返回值:显示待处理消息的统计信息或详细列表。
- 8、XCLAIM:转移消息所有权,语法:
XCLAIM stream-key group-name consumer-name min-idle-time message-id [message-id ...] [IDLE ms] [RETRYCOUNT count] [FORCE]- min-idle-time:消息未被处理的最小时间(毫秒)。
- IDLE/RETRYCOUNT:更新消息的空闲时间和重试次数。
- FORCE:强制转移未确认的消息。
- 9、XINFO:查看流或消费者组信息,语法:
XINFO [STREAM stream-key | GROUPS stream-key | CONSUMERS stream-key group-name]- STREAM:显示流的详细信息(如长度、最后ID)。
- GROUPS:显示流的所有消费者组信息。
- CONSUMERS:显示指定组的所有消费者及其状态。
- 10、XINFO GROUPS:查看流的所有消费者组,语法:
XINFO GROUPS stream-key- 返回值:包含组名、消费者数量、待处理消息数等信息。
- 11、XINFO STREAM:查看流的详细信息,语法:
XINFO STREAM stream-key- 返回值:流的元数据(如长度、第一个/最后一个消息ID)。
6.3、消费者组的详细工作流程
- 创建消费者组
- 可以指定起始消费位置(如 0-0 表示从第一条消息开始)
- MKSTREAM 选项在 Stream 不存在时创建它
- 消费者读取消息
- 多个消费者可以同时从同一组读取消息,实现负载均衡
- COUNT 参数指定每次读取的最大消息数
- BLOCK 参数支持阻塞读取,等待新消息到达
- 消息确认机制
- 消费者处理完消息后必须调用 XACK 确认
- 未确认的消息会被视为待处理,在消费者故障时可重新分配
- 处理消费者故障
- 长时间未确认的消息会被标记为 “pending”
- 可以使用 XPENDING 命令查看 pending 消息
- 可以使用 XCLAIM 命令将 pending 消息重新分配给其他消费者
6.4、注意事项
- Redis毕竟不是专业的消息中间件,适合一些简单的场景,使用时要考虑内存压力问题。
- 生产上如果要使用,要考虑以后是否要拓展,尽量还是使用专业的消息中间件。
- 要合理设置 MAXLEN:根据业务需求设置 Stream 最大长度,避免内存溢出
- 批量操作:使用 Pipeline 批量发送命令,减少网络往返
- 注意pending 消息管理:定期处理长时间未确认的消息,避免积压
全部评论